Week II: Basic Biological Mechanisms and Data¶
Biological systems are working in a complex interaction network based on physical, chemical and biochemical principles. The building blocks of the biological systems are macromolecules (polymers) which are carbohydrates, lipids, nucleic acids (DNA, RNA) and proteins that are built from smaller organic molecules called monomers such as monosaccharides, glycerol, fatty acids, nucleotides, and aminoacids.
Central Dogma of Molecular Biology¶
The Central Dogma of Molecular Biology describes the flow of biological information (Figure 1). DNA is the source of the knowledge, as a relatively long-lived information storage molecule. Information is copied into new DNA molecules by the process called replication, or flows into messenger RNA (mRNA), during the process called transcription. mRNA, a relatively short-lived nucleic acid, transfers information to ribosomes which synthesize protein molecules during the process called translation. Proteins are main characters of the stage as the building blocks of life. They serve a variety of purposes, ranging from molecular machines such as enzymes to structural molecules. Proteins play a major role in replication, transcription and translation, too. There are some circumstances where information flows differently, for example RNA viruses encode their genomes in RNA, which can be reverse transcribed to DNA in a host cell. However, proteins are terminal output of all. We have not discovered a natural process that can work backwards to re-create the RNA or DNA from protein.

Figure 1. The central dogma of molecular biology represents information flow in biological systems. Blue pathways are generally observed in cellular life. Red pathways are observed in special cases such as RNA viruses. (From Wikimedia Commons).
{kind=link}
Deoxyribonucleic Acid (DNA)¶
Deoxyribonucleic acid (DNA) serves as the repository for the genetic instructions governing the growth and operation of cells. DNA consists of a pair of strands linking each other, giving the appearance of a coiled ladder, called as double helix structure. Each strand possesses a supporting structure composed of alternating sugar (deoxyribose) and phosphate groups. Adhering to each sugar is one of four nucleotide bases: adenine (A), cytosine (C), guanine (G), or thymine (T). The two strands are linked by hydrogen bonds formed between specific base pairs: adenine pairs with thymine, and cytosine pairs with guanine. The arrangement of these bases along the DNA's backbone contains essential biological data, such as the instructions for producing RNA and proteins molecules.
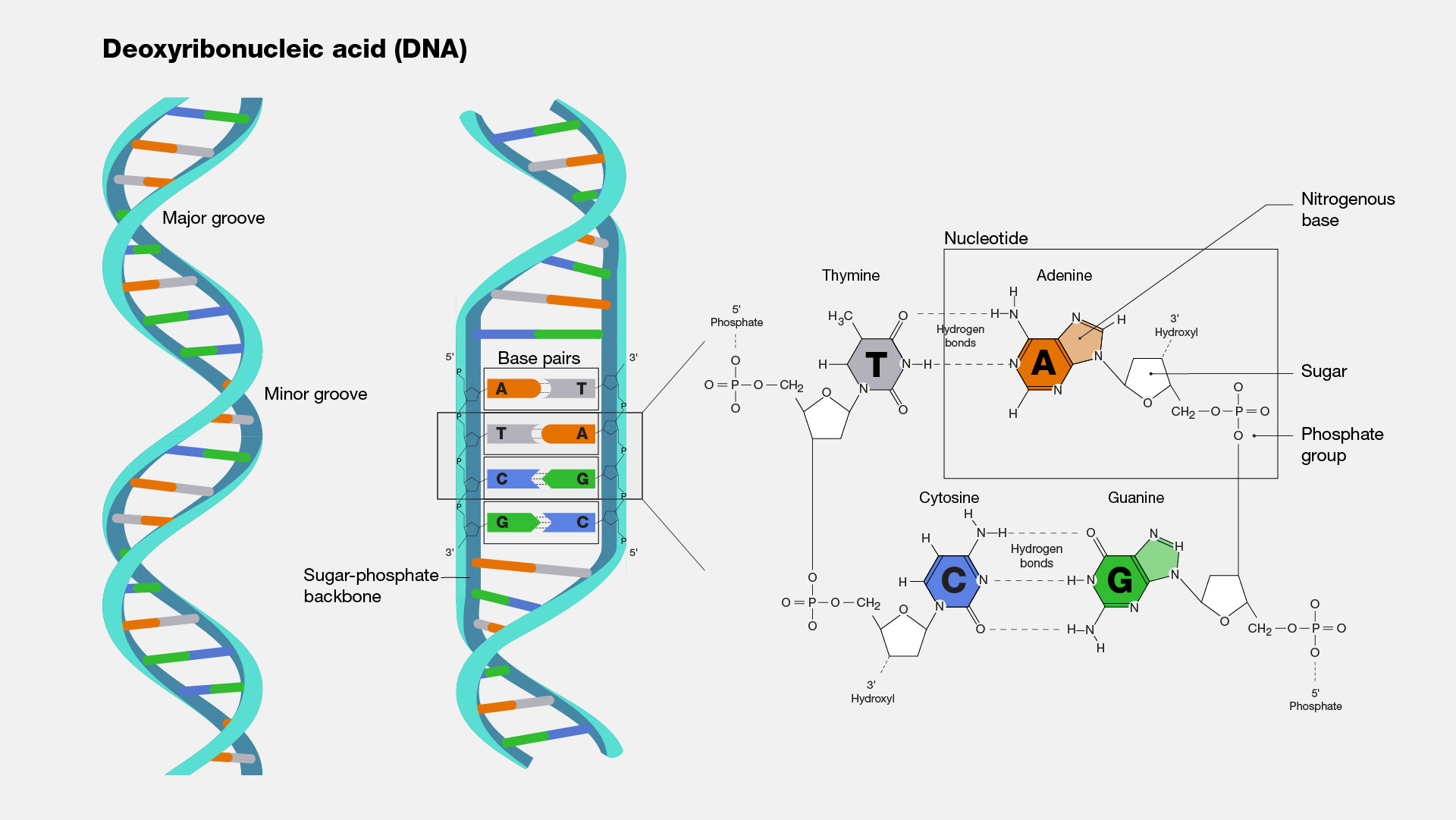
Figure 2. The structure of DNA and deoxyribo nucleotides (From NIH Genetics Glossary)
A single instance of the human genome comprises approximately 3 billion DNA base pairs, distributed among 23 chromosomes that vary in size from about 50 million to 300 million base pairs. Since these bases pair up, with one determining the other in each pair, scientists generally represent DNA sequences as single-letter strings. DNA sequencing is the process of determining the precise order of base pairs within a specific DNA segment or an entire genome. One of the primary objectives of the Human Genome Project was to produce the first high-quality sequence of the human genome. Although it succeeded in sequencing over 90% of the human genome, it took nearly two more decades to sequence the remaining portions, which were notably rich in highly repetitive and challenging-to-sequence DNA segments.
DNA defines our individual identities, as it is what makes each of us unique. While we may appear distinct from one another, in reality, our DNA is 99.9% identical, providing a common genetic foundation that guides our development and unites people around the world. The remaining 0.1% accounts for variations that contribute to our uniqueness. When these genetic distinctions interact with environmental and social factors, they influence our abilities, health, and behavior.
Chromosome¶
Chromosomes are elongated structures comprised of both proteins and DNA molecule, and their primary role is to convey genetic information as it's passed from one cell to another. Within the cells of plants and animals, including humans, chromosomes are housed within the cell's nucleus. In the case of humans, there are 22 pairs of chromosomes referred to as autosomes, and one pair of sex chromosomes, which can be XX (for females) or XY (for males), totaling 46 chromosomes. Each of these pairs includes two chromosomes, with one originating from each parent. This means that children inherit an equal share of chromosomes, with half originating from their mother and the other half from their father. Chromosomes become visible under a microscope when the cell's nucleus dissolves during cell division.
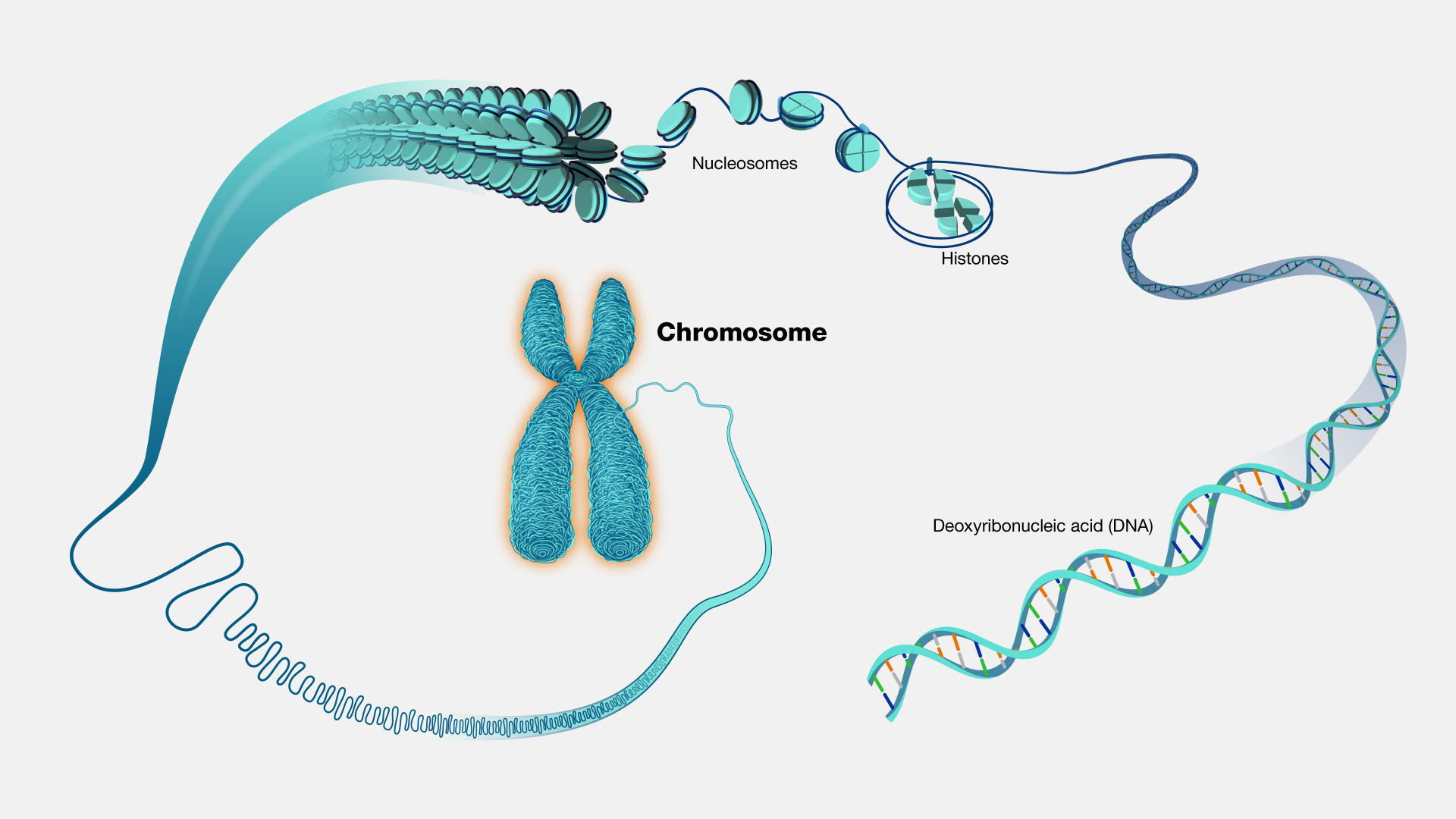
Figure 3. The structures from DNA to chromosome (From NIH Genetics Glossary)
Chromosomes exhibit variations in quantity and configuration across different organisms. Most bacteria typically possess one or two circular chromosomes, whereas humans, as well as other animals and plants, feature linear chromosomes. In fact, each species of plant and animal has a specific and consistent number of chromosomes. For instance, fruit flies have four pairs of chromosomes, rice plants have 12, and dogs have 39. In humans, the twenty-third pair comprises the sex chromosomes, with the initial 22 pairs known as autosomes. Generally, biologically female individuals carry two X chromosomes (XX), while biologically male individuals have one X and one Y chromosome (XY). However, there are exceptions to these patterns.
Additionally, chromosomes differ in size. The human X chromosome, for instance, is roughly three times larger than the Y chromosome and contains approximately 900 genes, whereas the Y chromosome has around 55 genes. Chromosomes have a unique structure that allows DNA to be tightly coiled around protein complexes known as histones. This packaging is essential because without it, DNA molecules would be too long to fit within cells. To illustrate, if all the DNA molecules in a single human cell were to be unwound from their histones and laid end-to-end, they would stretch a length of 1.8 m.
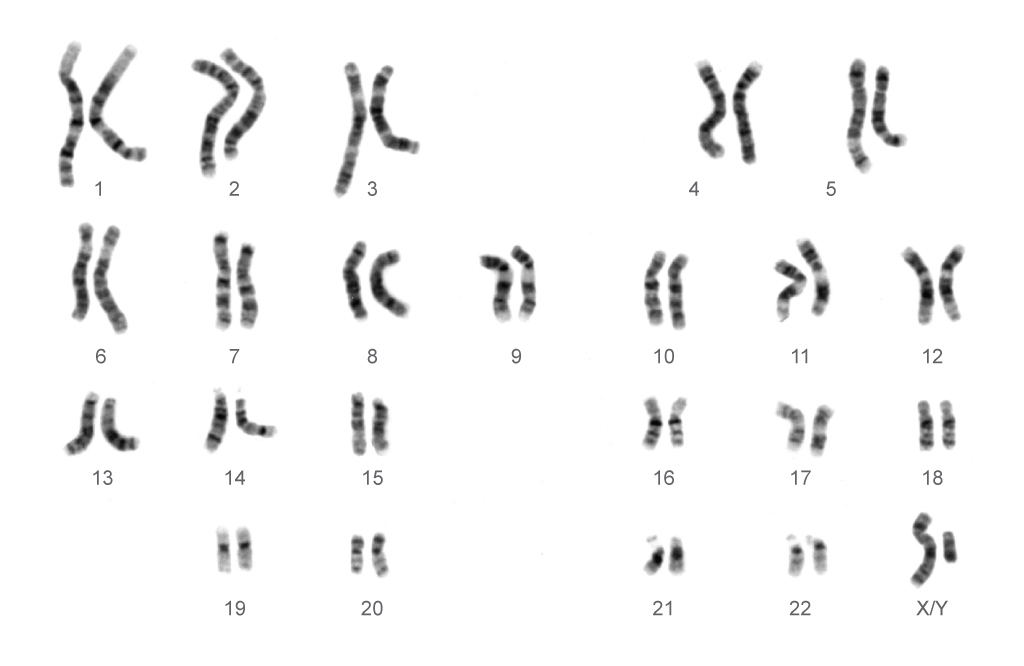
Figure 4. Karyotype visualization of human chromosomes (From NIH About Genomics)
Mapping is the process of determining the relative positions of specific landmarks or markers, such as genes, genetic variants, and other significant DNA sequences, within a chromosome or genome. Traditionally, there have been two approaches to mapping: physical mapping, which constructs maps based on physical distances between these landmarks, and genetic mapping, which constructs maps based on how often two landmarks are inherited together.
A genetic map, also known as a linkage map, illustrates the relative positions of genetic markers, which represent sites of genomic variations, on a chromosome. This type of map relies on the principle of genetic linkage, refering to the proximity of genes or other DNA sequences to one another on the same chromosome. The closer two genes or sequences are on a chromosome, the greater the likelihood that they will be inherited together. By studying inheritance patterns, we can determine the relative order and positions of genetic markers along a chromosome. Gene mapping involves identifying the specific locations of genes on chromosomes. Nowadays, the most efficient approach to gene mapping is to sequence the genome and then employ computer programs to analyze the sequence and determine the gene's location.
A locus, within the realm of genomics, denotes a physical site or position within a genome, such as a gene or another noteworthy DNA segment, somewhat analogous to a street address. The plural form of locus is loci.
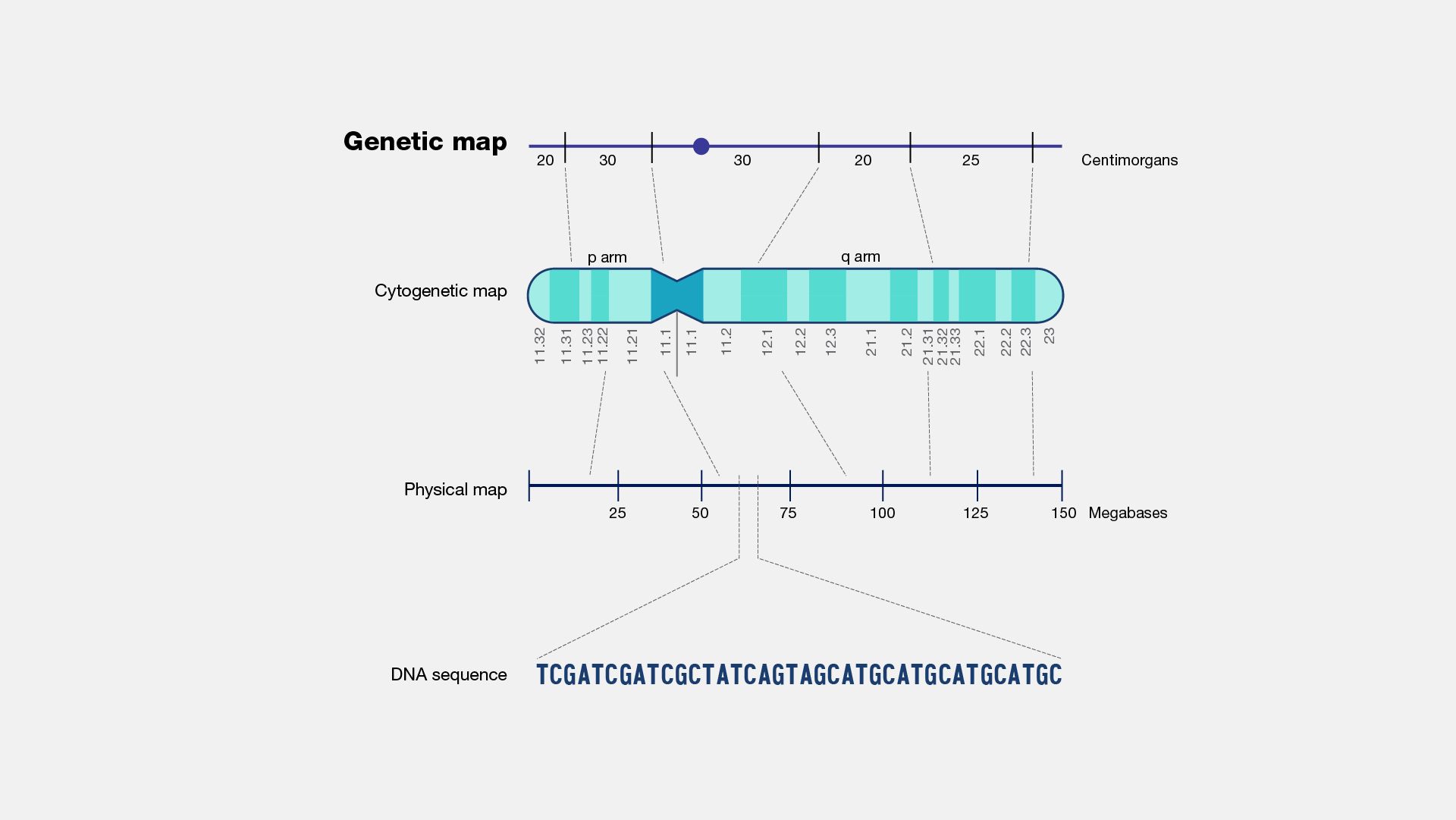
Figure 5. Mapping strategies of DNA elements (From NIH Genetics Glossary)
An allele is one of two or more variations of a DNA sequence, which can be as small as a single base or a segment of bases, found at a particular location in the genome. When it comes to any genomic location with such variability, an individual inherits two alleles, one from each parent. If these two alleles are identical, the individual is said to be homozygous for that allele. If the alleles differ, the individual is considered heterozygous.
A genotype represents the specific type of variant present at a particular location, known as a locus, in the genome. This can be symbolically denoted, for instance, as BB, Bb, or bb to describe a given variant within a gene. Alternatively, genotypes can be expressed through the actual DNA sequence at a specific location, such as CC, CT, or TT. Through techniques like DNA sequencing, genotypes at millions of locations within the genome can be determined in a single experiment. Some genotypes contribute to an individual's observable characteristics, which are referred to as the phenotype.
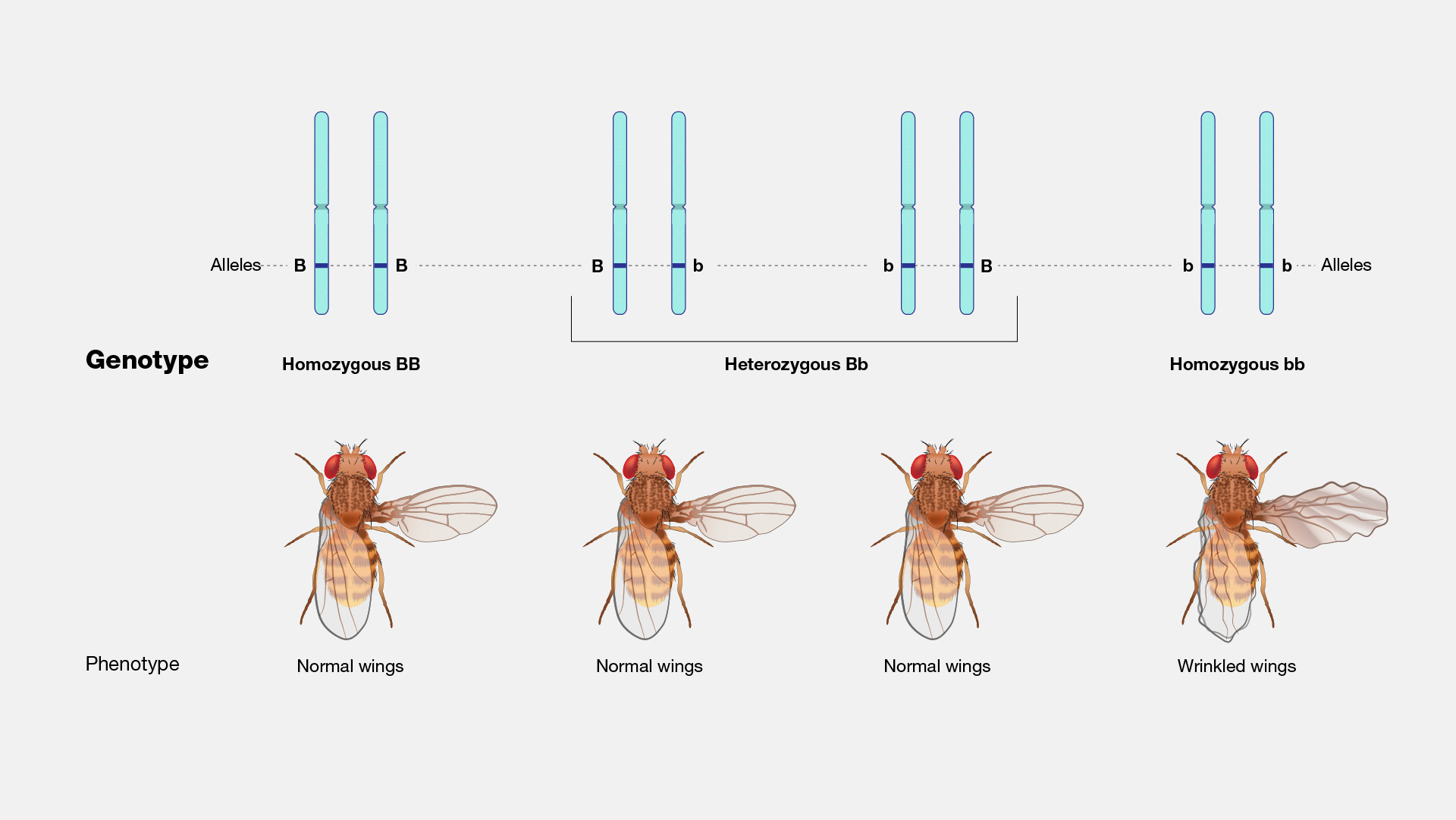
Figure 6. Phenotype depends on the genotype with different allele combinations (From NIH Genetics Glossary)
In the context of genetics, inheritance pertains to the transmission of genetic traits or variations encoded in DNA from one generation to the next during the process of reproduction. The principles of Mendelian genetics govern how inheritance occurs, and these rules dictate the passage of genotypic and, consequently, phenotypic characteristics to subsequent generations.
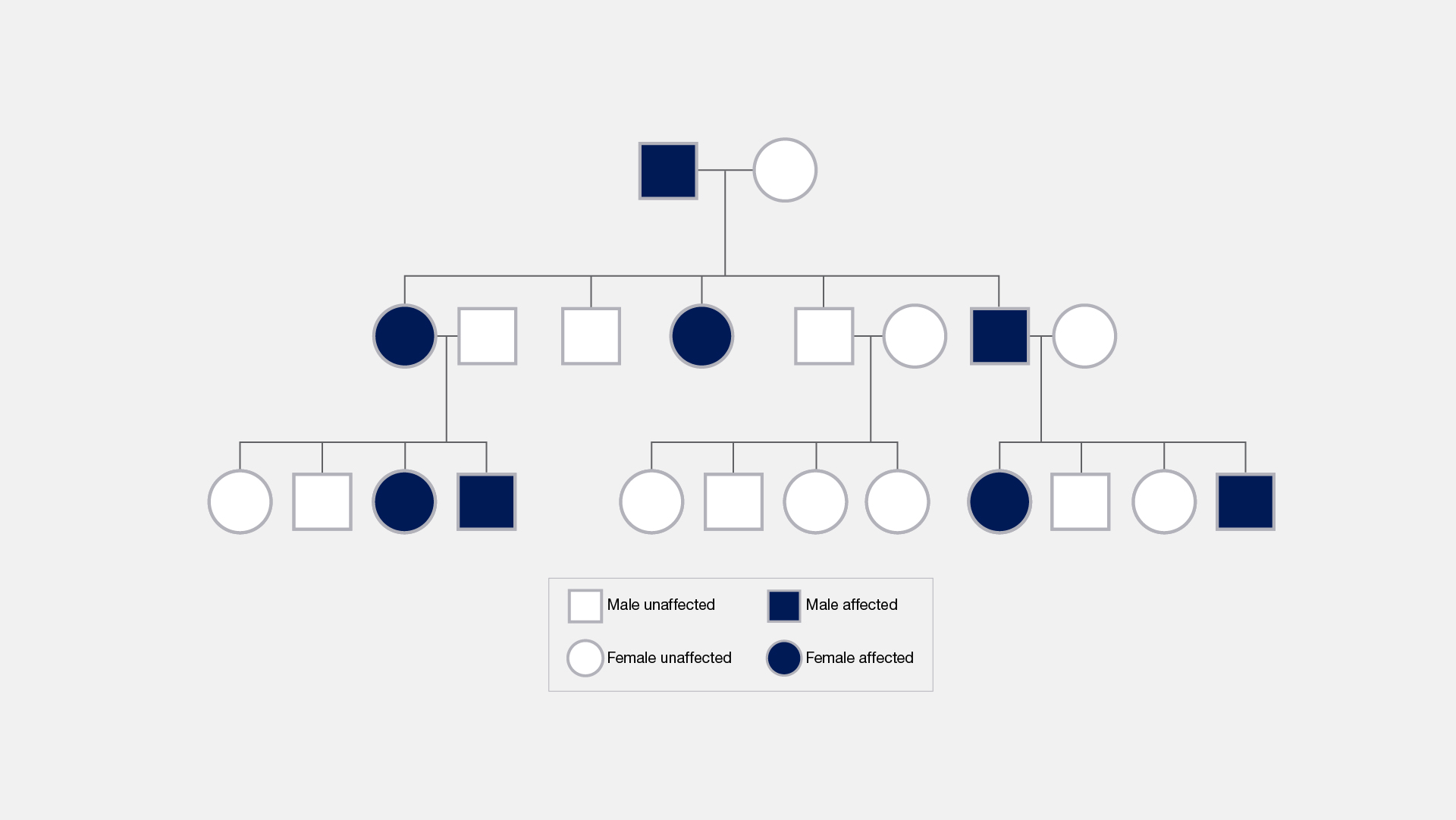
Figure 7. A pedigree illustrating the passage of a specific trait or health condition across multiple generations within a family. (From NIH Genetics Glossary)
Chromatin¶
Chromatin is a combination of DNA and proteins, including histones, which collectively constitute the chromosomes within the cells of humans and other advanced organisms. These histone proteins play a crucial role in condensing the vast amount of DNA in a genome into an extremely compact structure that can reside within the cell nucleus. Initially, DNA molecules coil around histone proteins, creating a beaded structure known as nucleosomes. These nucleosomes then aggregate and compact to create a fibrous substance referred to as chromatin. Chromatin fibers have the ability to uncoil when DNA replication and transcription processes occur. During cell replication, duplicated chromatin undergoes additional condensation, making them resemble chromosomes that are visible under a microscope. These chromosomes are then divided between daughter cells during cell division. In normal life of the cell DNA is existing in chromatin fiber or uncoiled, naked form. Naked DNA has the form that DNA is ready to transcribed.
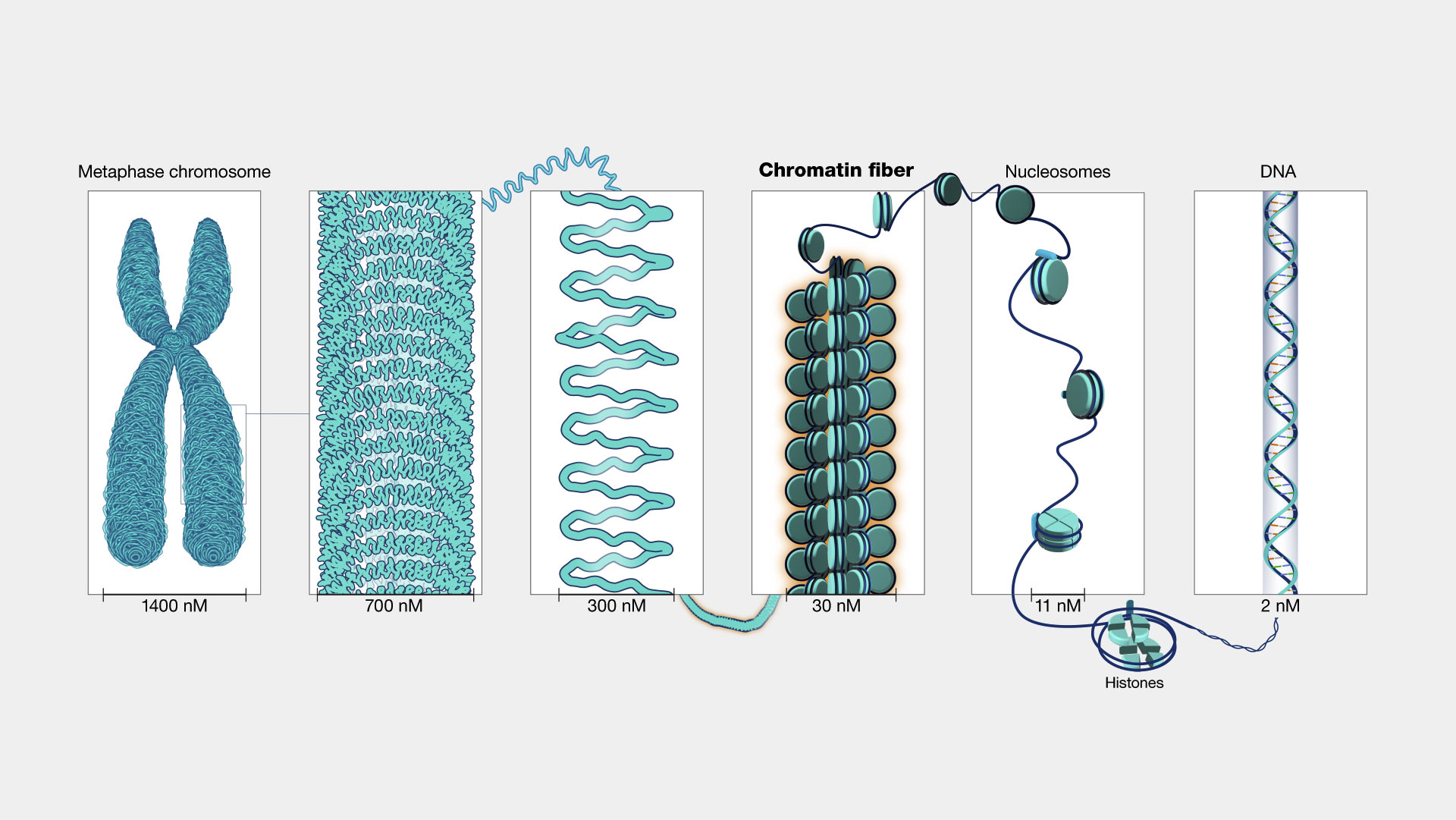
Figure 8. Different stages of DNA condensation (From NIH Genetics Glossary)
Nucleosome¶
A nucleosome serves as the fundamental repeating unit within chromatin, the structure found within the cell's nucleus. In humans, this is crucial because approximately 1.8 m of DNA needs to be compacted into a nucleus that is smaller in diameter than a human hair. Nucleosomes are instrumental in this compacting process. Each individual nucleosome comprises roughly 150 base pairs of DNA, which are wound around a central core of histone proteins. As chromatin forms into a chromosome, these nucleosomes undergo repetitive folding to further constrict and consolidate the packaged DNA.
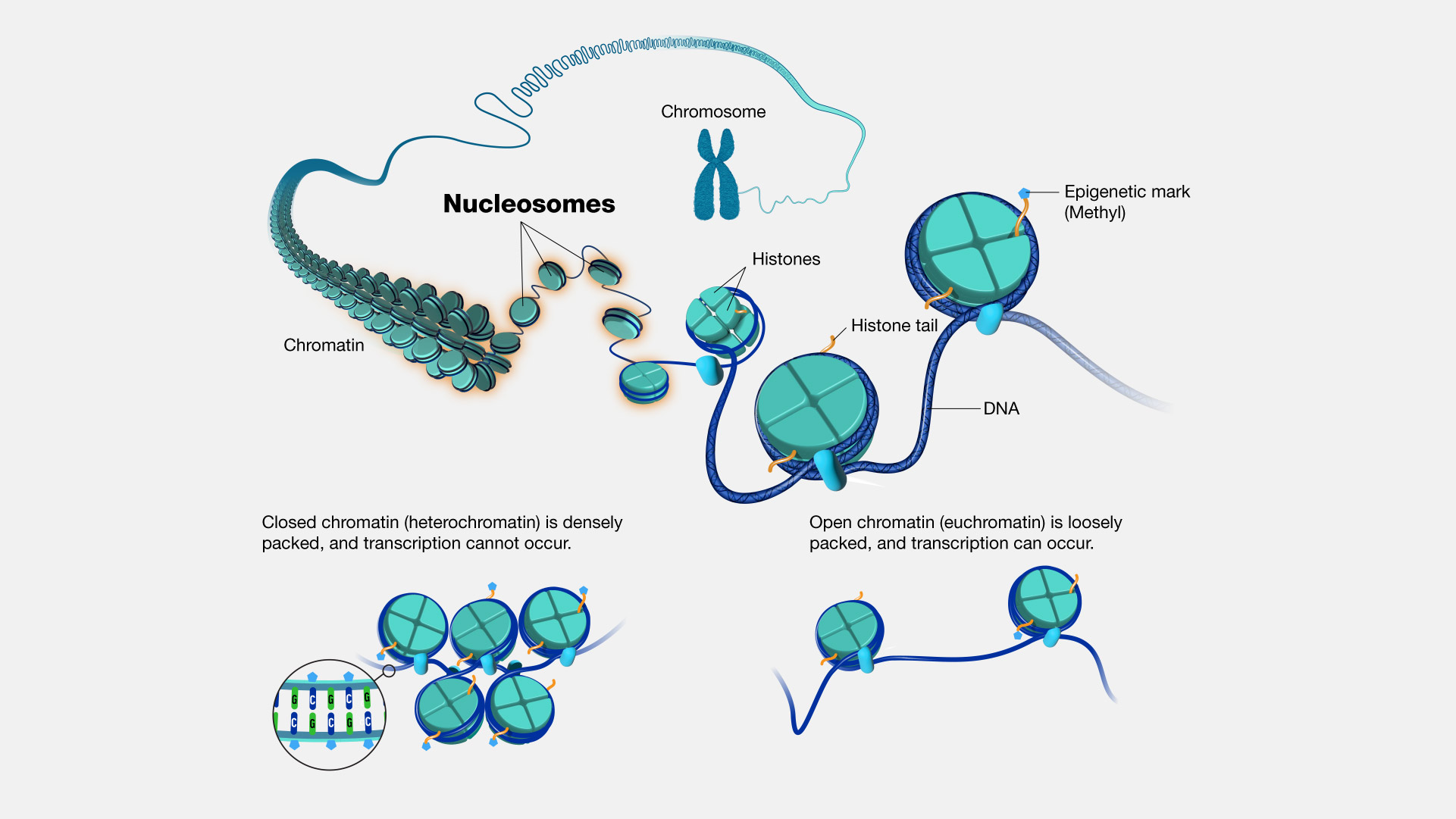
Figure 9. The structure of nucleosomes and histone proteins (From NIH Genetics Glossary)
Histone¶
Histones are proteins that serve a structural role for chromosomes. Within each chromosome, there exists an extensive DNA molecule that needs to fit inside the cell nucleus. To achieve this, DNA coils around complexes formed by histone proteins, resulting in a more compact chromosome structure. Additionally, histones are involved in regulating gene expression, too.
Eight histone proteins can assemble to create a structure known as a nucleosome, resembling a miniature spool around which DNA can wind. Therefore, histones are instrumental in maintaining the organization of the genome and keeping it neatly packaged within a cell. What's intriguing is that histone proteins can be modified in ways that are akin to displaying "open" or "closed" signs for a business. When histones near a gene bear certain modifications, like "open" signs, they indicate that a particular gene is active or "on" in a specific cell. Conversely, if these histones have a distinct set of modifications resembling "closed" signs, they signify that the gene is inactive or "off" in that cell. The study of histones and their modifications has provided valuable insights into which genes are active or inactive in various cell types. This knowledge is crucial for understanding the functioning of normal cells and how it may differ in abnormal cells contributing to diseases.
Epigenetics¶
Epigenetics (or epigenomics), is a field of research dedicated to the examination of modifications on histone tails or DNA that do not entail changes in the underlying genetic sequence. DNA's constituent letters and the histone proteins that interact with it can undergo chemical alterations that influence the extent to which genes are activated or repressed. Some of these epigenetic modifications can be transmitted from a parent cell to its descendant during cell division, or even from one generation to the next. The entirety of these epigenetic alterations within a genome is termed an epigenome.
Within a gene, both the DNA's constituent letters and the associated proteins are not in their natural state but rather adorned with chemical modifications that regulate when, where, and how the gene is switched on or off. Epigenetics, or epigenomics, investigates the mechanisms through which specific epigenetic changes can be inherited from one generation to the next.
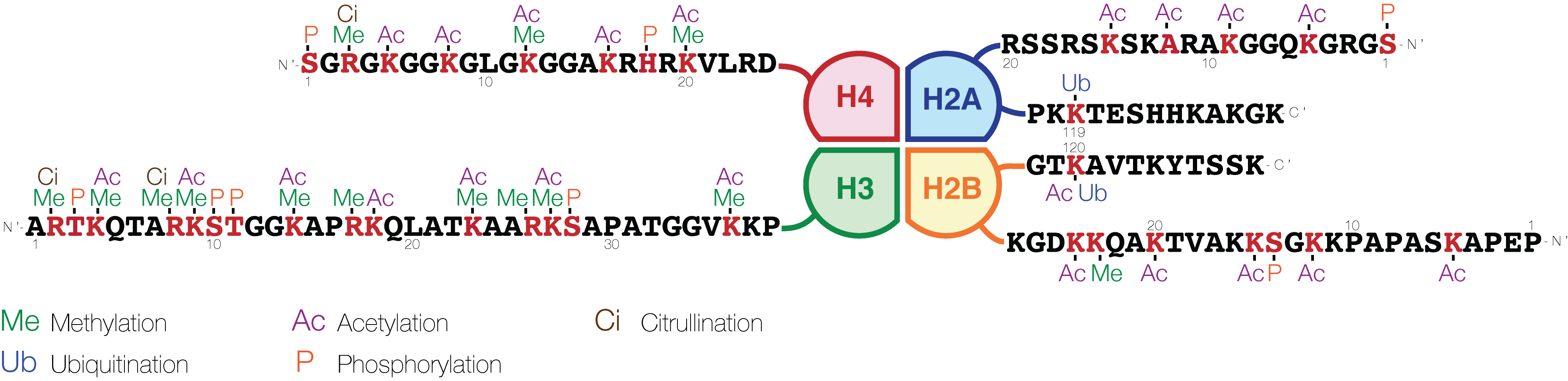
Figure 10. Epigenetic modifications of histone tails (From Wikipedia)
{kind=link}
DNA Methylation¶
Methylation represents a chemical modification that can occur in DNA and other molecules, and it has the capacity to persist as cells divide to generate more cells. When methylation takes place in DNA, it can bring about alterations in gene expression. In this process, chemical markers known as methyl groups attach to specific locations within the DNA, effectively switching genes on or off. This mechanism regulates the production of proteins encoded by the gene.
Methylation is also utilized to distinguish different genome types. For instance, various bacteria methylate distinct DNA sequences. Some bacteria might methylate the sequence GAATTC, enabling them to differentiate their own DNA from foreign invading DNA. This methylation process is fundamental in the generation of restriction enzymes within bacterial cells, which are used to identify foreign DNA without harming the cell's own DNA.
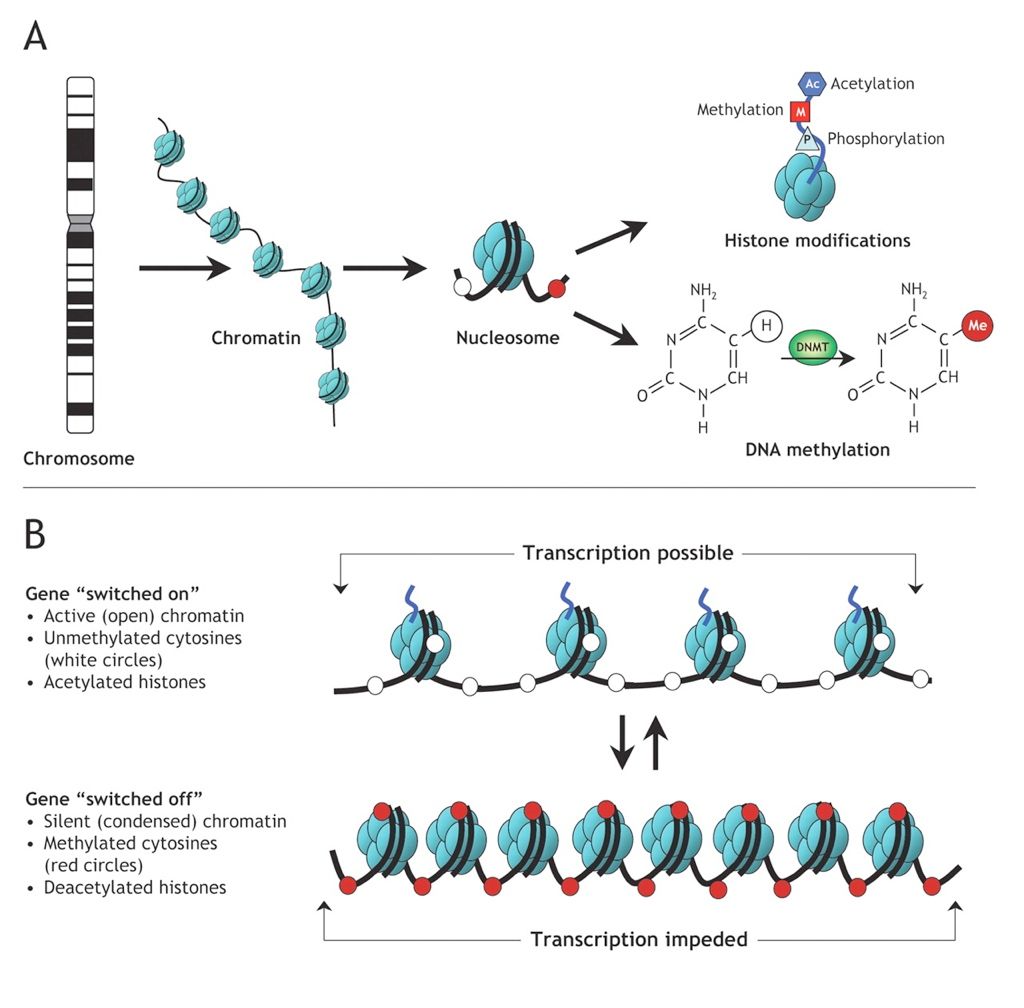
Figure 11. DNA methylation and histone modifications effect on gene regulation (From Galaxy Training)
Gene¶
A gene is widely recognized as the fundamental hereditary unit, passed down from parents to offspring, carrying the instructions required to determine physical and biological traits. The majority of genes are responsible for encoding specific proteins or portions of proteins, each serving diverse functions within the body.
The precise definition of the term "gene" has been a topic of scientific discussion for a considerable time. One straightforward way to understand it is as follows: Proteins constitute the essential building blocks of our cells and tissues, while genes represent the genomic segments that store the instructions for producing these proteins. For example, the human genome comprises around 20,000 protein-coding genes. Intriguingly, all the information necessary for these 20,000 protein-coding genes is contained within a mere 1.5% of the entire human genome.
A more inclusive interpretation of a gene encompasses segments of DNA that carry instructions for producing an RNA molecule with a functional role other than directly coding for a protein. These are sometimes referred to as RNA genes.
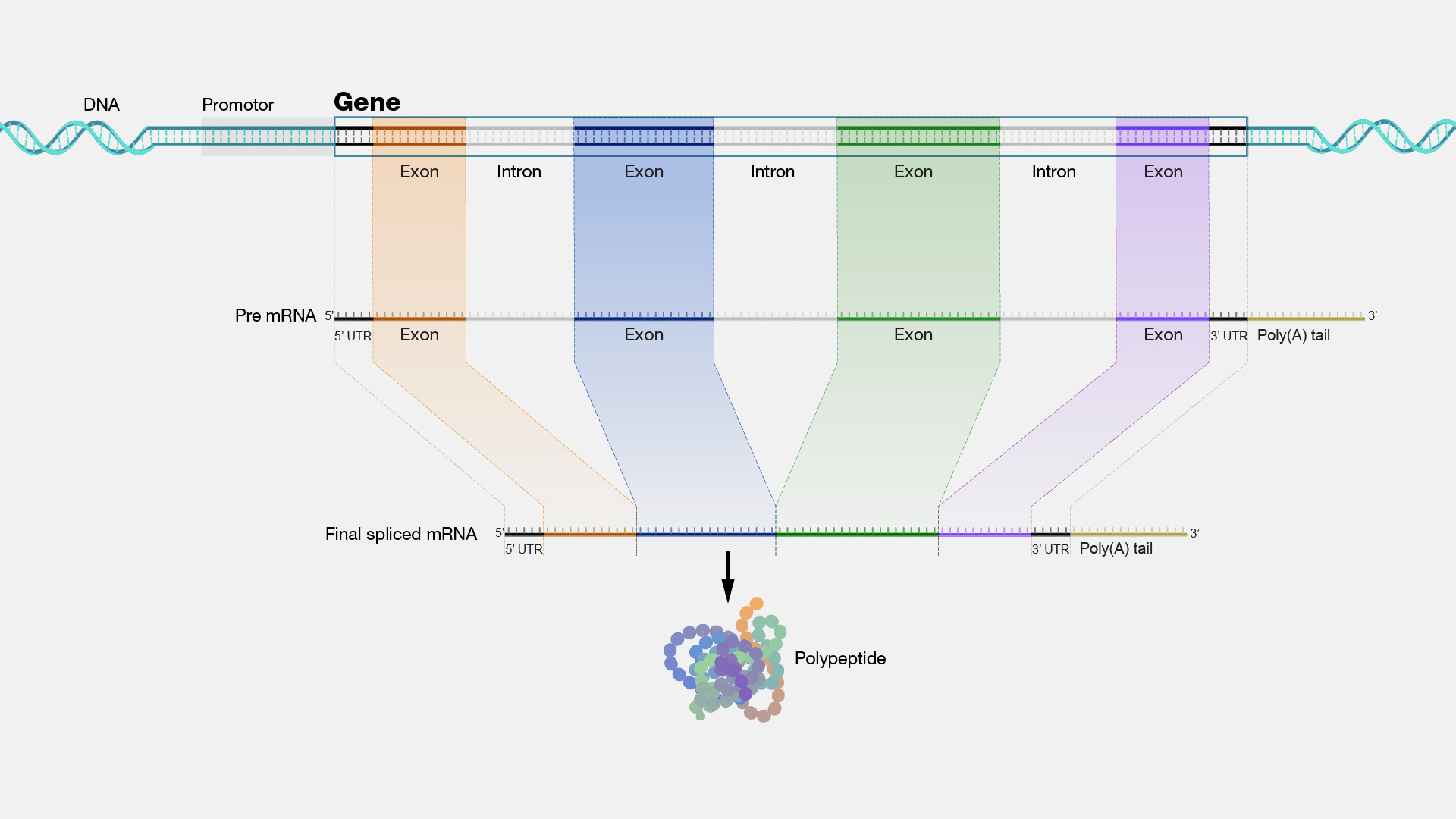
Figure 12. The elements of a protein coding gene (From NIH Genetics Glossary)
Exon¶
An exon is a genomic segment that becomes part of an mRNA molecule. Some exons are coding, meaning they contain instructions for producing a protein, while others are non-coding. Genes in the genome comprise both exons and introns. Initially, when RNA is transcribed, it forms an extensive molecule. The vital components of this RNA are the exons. Substantial sections of RNA are subsequently removed. It's crucial to clarify that the use of "excised" doesn't imply the vanishing of exons. Exons are what remain in the mature mRNA, eventually coding for amino acids. It's easy to forget whether exons or introns code for amino acids, but let me clarify: exons encode amino acids.
Intron¶
An intron is a segment situated within a gene, but it does not persist in the final mature mRNA following gene transcription. Introns do not contain the code for the amino acids that constitute the protein specified by that gene. Most protein-coding genes in the human genome encompass both exons and introns. During gene transcription, introns are eliminated during the splicing process, leaving only exons in the mature mRNA, which determine the proteins produced. In numerous genes, introns tend to be much lengthier than exons. Introns might contain sequences that regulate gene expression, transcription, and mRNA processing.
Promoter¶
In genomics, a promoter is a DNA region located upstream of a gene, where critical proteins, including RNA polymerase and transcription factors, bind to initiate gene transcription. This transcription process leads to the generation of an RNA molecule, such as mRNA. Promoters can be highly intricate and often cooperate with other DNA regions, known as enhancers, to ensure robust gene transcription. Investigating how DNA flexes and brings the enhancer and promoter into close proximity for transcription initiation has been a captivating area of research. In some instances, when examining human diseases, DNA mutations are not in the coding region but rather in the promoter region. This introduces a different approach to addressing such sequence errors.
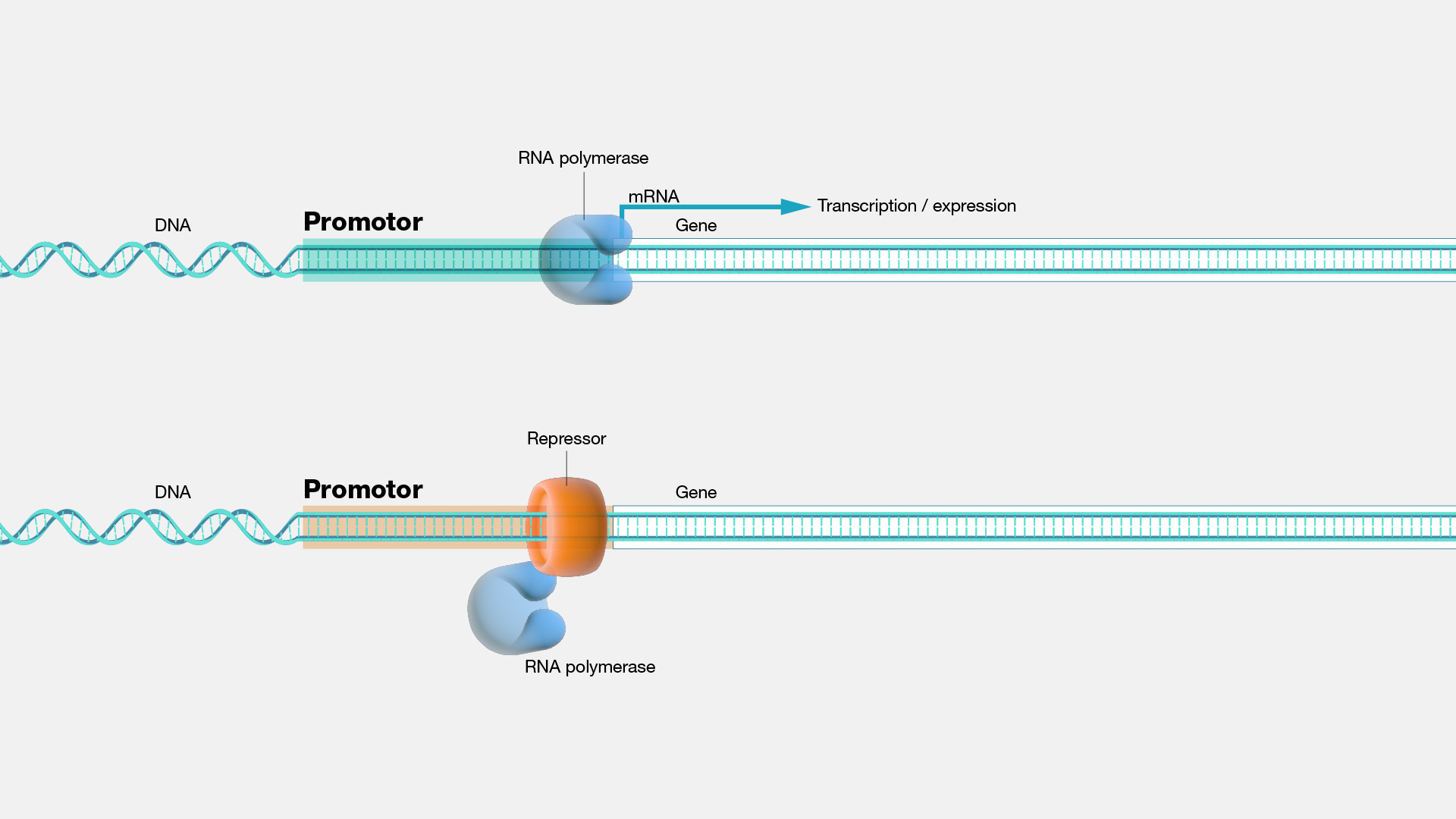
Figure 13. The role of promoter in transcription and gene regulation (From NIH Genetics Glossary)
Gene Regulation¶
Gene regulation encompasses the intricate procedures employed to manage when, where, and to what extent genes are transcribed. This intricate process is governed by a range of mechanisms, involving regulatory proteins and chemical modifications of DNA and histone tails. Gene regulation is pivotal in enabling an organism to adapt to alterations in its environment.
Gene regulation is a fundamental cellular process employed to generate the transcripts that subsequently lead to the production of proteins. It represents an essential function for which a significant portion of a cell's energy is allocated. Moreover, a substantial portion of a cell's genome is likely dedicated to the regulation of genes, allowing for precise adjustments in how a cell reacts to environmental signals, the organism's development, or the repair processes.
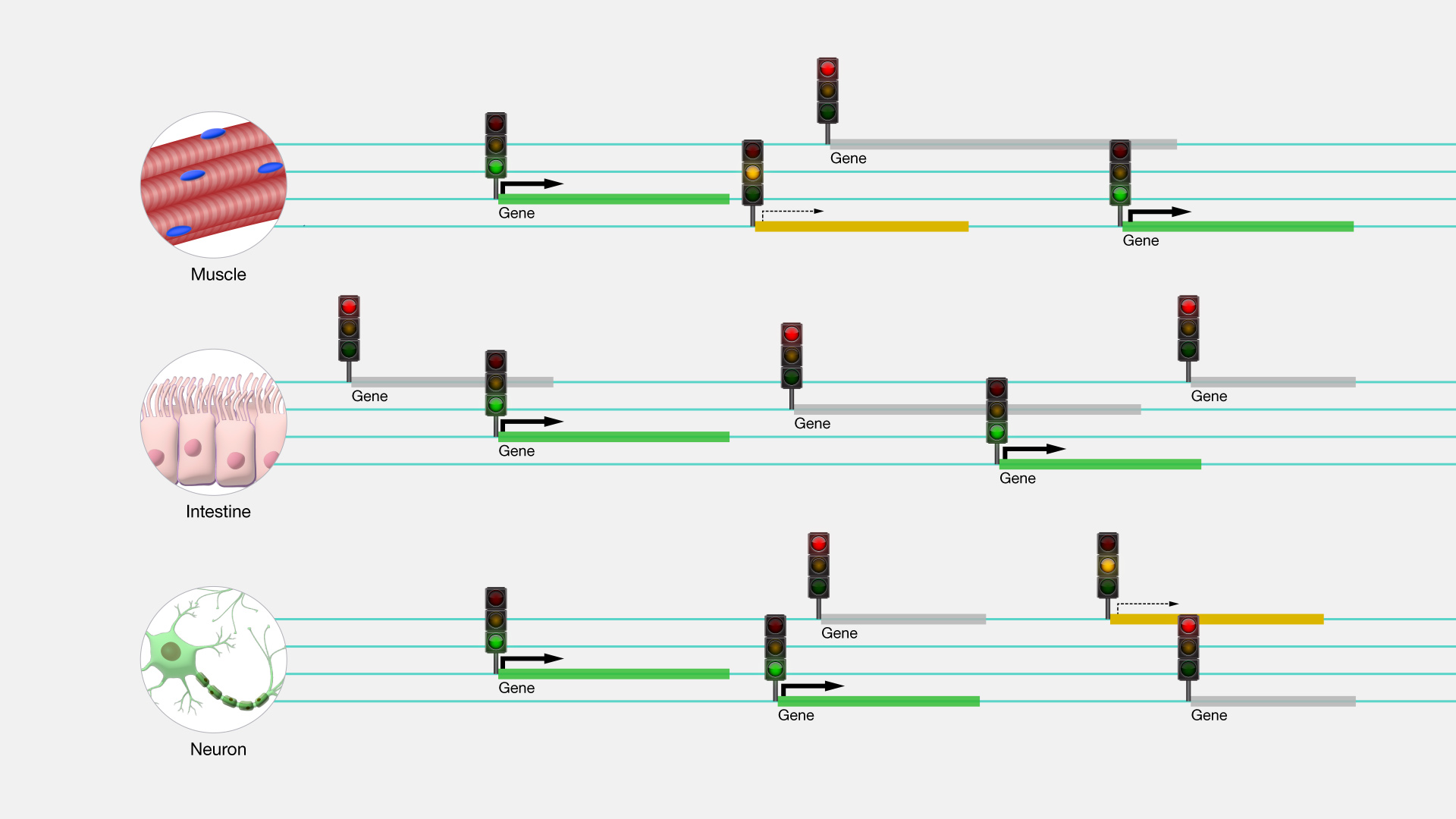
Figure 14. Representation of gene ragulation (From NIH Genetics Glossary)
Gene expression¶
Gene expression is the process through which the information stored within a gene is transformed into a functional outcome. This is primarily achieved by transcribing RNA molecules, which can code for proteins or serve other functions. Visualize gene expression as both an "on/off switch" that regulates when and where RNA molecules and proteins are produced and as a "volume control" determining the quantity of these products. Gene expression is meticulously regulated and can significantly alter in varying conditions and within different cell types. RNA and protein products of numerous genes play a role in controlling the expression of other genes. The location, timing, and extent of gene expression can be assessed by measuring the functional activity of a gene product or by observing a trait linked to a particular gene.
With modern technologies, we possess the capability to measure mRNA expression for every gene within the entire genome, sometimes even in individual cells. This is a potent tool for determining which genes are active, the degree of their activity, and where they are active. Traditionally, gene expression can also be gauged by examining observable traits, such as assessing protein activity. If we can measure the activity of a protein, we can infer that the gene encoding it is "switched on." Moreover, we can identify patterns in traits. For instance, when a butterfly wing exhibits various colors due to different genes being activated in various regions, we can measure gene expression simply by examining and documenting the locations of these colors on the wing.
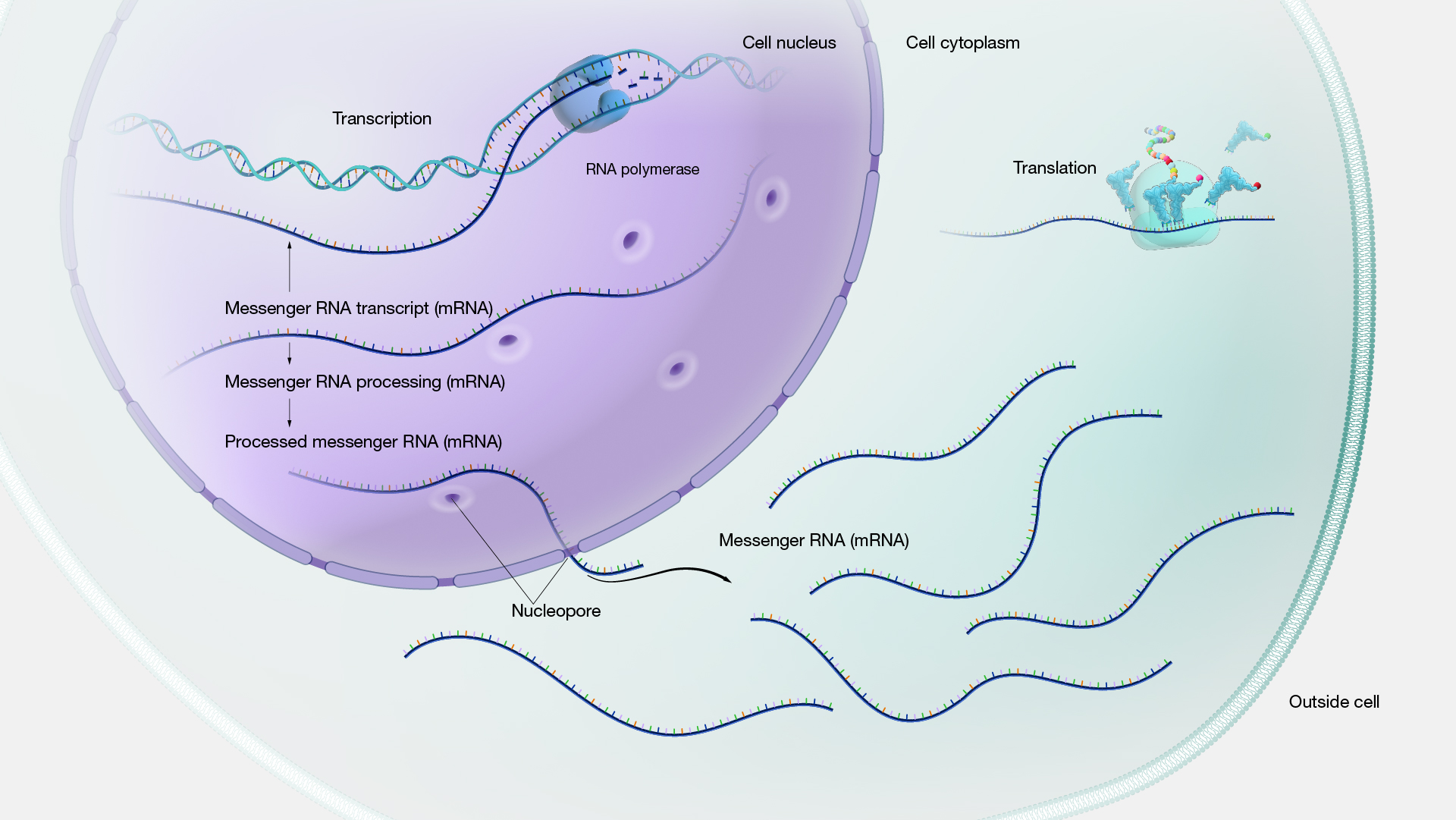
Figure 15. Gene expression levels in an eukaryotic cell (From NIH Genetics Glossary)
Transcription¶
Transcription denotes the procedure of creating an RNA replica of a gene's DNA sequence. This replicated form, known as messenger RNA (mRNA), serves as the carrier of the genetic information for producing the gene's corresponding protein. In complex organisms like humans, the mRNA migrates from the cell nucleus to the aqueous interior of the cell called the cytoplasm, where it is employed in the synthesis of the encoded protein.
Analogously, transcription is akin to the process of translating a book from one language to another. While DNA is a more resilient molecule, RNA serves as the more versatile and widespread biological language.
Ribonucleic Acid (RNA)¶
Ribonucleic acid (RNA), is a nucleic acid that exists in every living cell and shares structural similarities with DNA. However, RNA is typically single-stranded, unlike the double-stranded structure of DNA. RNA molecules feature a backbone comprising alternating phosphate groups and the sugar ribose, distinct from the deoxyribose present in DNA. Each sugar in RNA is linked to one of four bases: adenine (A), uracil (U), cytosine (C), or guanine (G). Various types of RNA are found in cells, including messenger RNA (mRNA), ribosomal RNA (rRNA), and transfer RNA (tRNA). Moreover, specific RNA molecules are involved in the regulation of gene expression. Certain viruses employ RNA as their genomic material.
RNA is the active form of nucleic acids that the body primarily utilizes to perform essential functions. It is responsible for constructing cells, responding to immune challenges, and transporting amino acids within the cell. RNA's critical role often goes underestimated. The different types of RNA, such as mRNA, tRNA, and rRNA, each have indispensable functions.
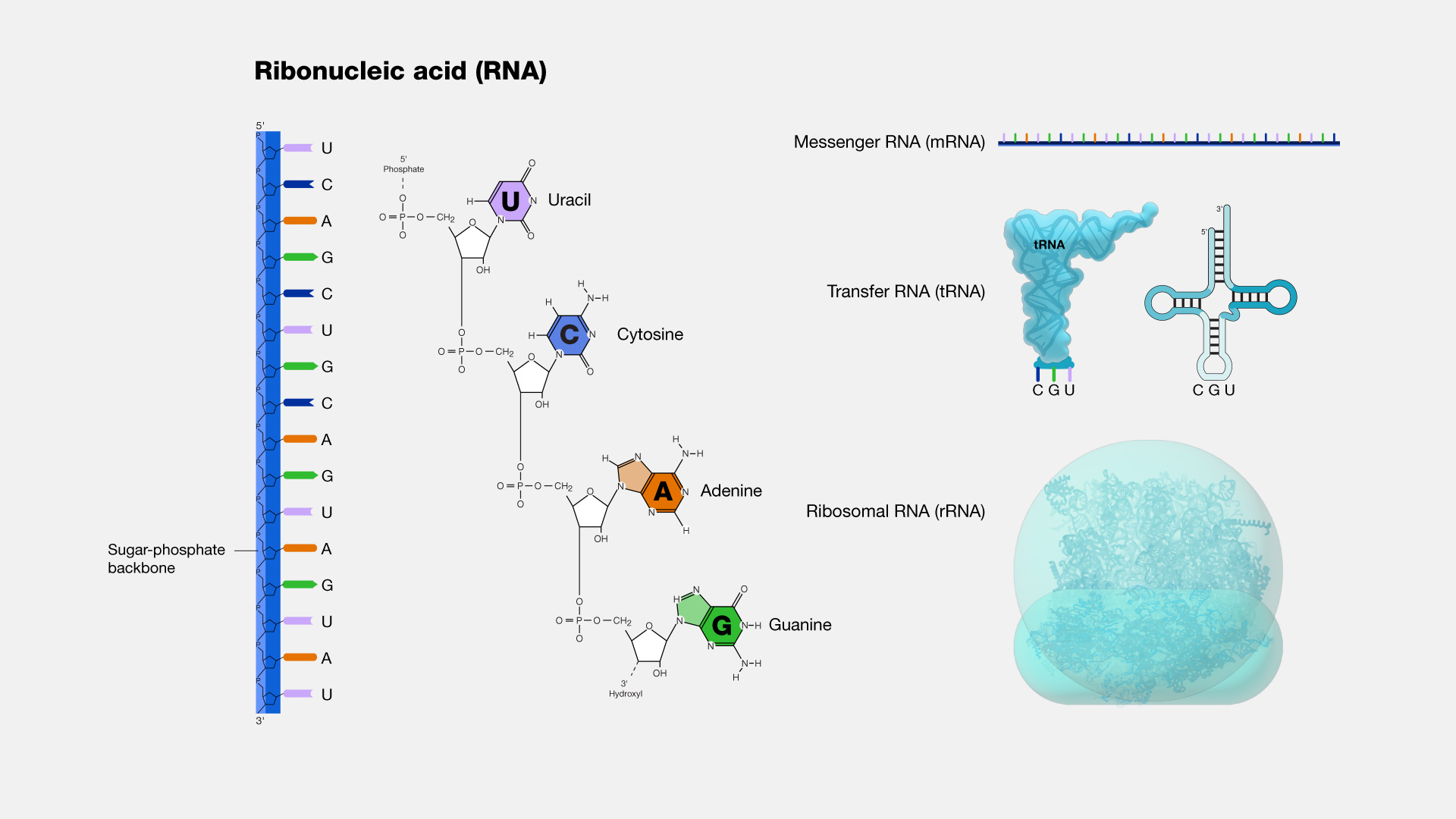
Figure 16. The structure of RNA and different RNA types (From NIH Genetics Glossary)
Messenger RNA (mRNA)¶
Messenger RNA (mRNA) is a single-stranded RNA type that plays a pivotal role in the process of protein synthesis. mRNA is synthesized from a DNA template during the transcription process. Its primary function is to transport genetic information for the production of proteins. In the cytoplasm, the ribosome reads the mRNA sequence and converts each three-base codon into the corresponding amino acid, thereby forms a growing protein chain.
While DNA resides within the cell's nucleus, the cell's ribosomes and other organelles facilitate the translation of DNA into functional proteins. Consequently, mRNA plays a fundamental role in the process of creating a living organism, serving as a crucial link between the genetic code of life and the actual construction of a cell.
Genetic Code¶
The genetic code refers to the directives found within a gene, which instruct a cell on the precise method for producing a particular protein. These instructions are composed using the four nucleotide bases of DNA, namely adenine (A), cytosine (C), guanine (G), and thymine (T) / uracil (U). The genetic code employs these bases in diverse arrangements to form three-letter "codons," each of which specifies the required amino acid at a specific position within the protein.
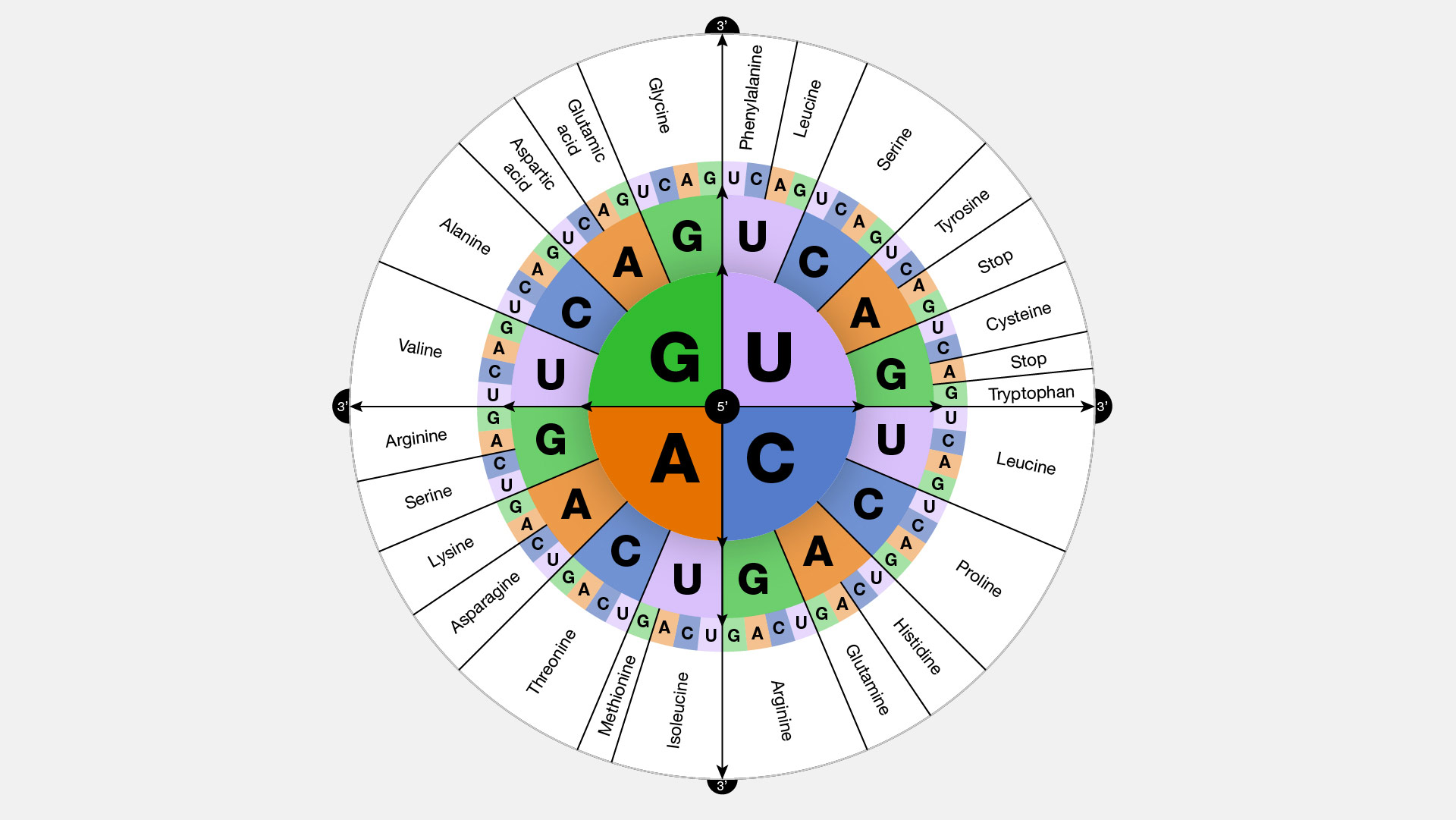
Figure 17. The genetic code of mRNA (From NIH Genetics Glossary)
Protein sequences are encoded in a base 4 system¶
DNA comprises four chemical compounds known as adenine, cytosine, guanine, and thymine, typically represented by the abbreviations A, C, G, and T. One of DNA's primary functions in biological organisms is to encode the amino acid sequence, or the primary structure of proteins. Similar to computer systems, this information is conveyed through discrete states, but in biological systems, there are four states instead of two. Each position in an exon of a protein-coding DNA sequence can contain one of these compounds, and the linear order of these compounds can transmit a message.
Proteins, when initially translated, are constructed from simpler components called amino acids. Most organisms employ 20 different amino acids in protein synthesis. Since there are four DNA bases (A, C, G, and T) and 20 amino acids, more than one base is needed to communicate which amino acid comes next in a protein, from DNA to the ribosome. The number of DNA bases required depends on how many messages are needed, which, in this instance, is 20 (representing the 20 amino acids). So, how many DNA bases are essential to encode the 20 canonical amino acids?
To calculate the number of messages that can be conveyed in a base four system with a given number of positions, the formula $4^n$ is used. With a single position (or one DNA base), four messages can be transmitted. Since four is less than 20, longer messages are needed to encode the 20 amino acids. A message composed of two bases enables the transmission of 16 messages ($4^2=16$), still less than 20, necessitating more bases. When the message comprises three bases, 64 messages can be sent ($4^3=64$), which is more than sufficient to encode all the amino acids, with some messages to spare. It's crucial to emphasize that the number of positions must be a whole number, and "2.5 bases of DNA" is not a meaningful quantity.
In reality, amino acids are encoded by three nucleotide bases, and these three-base messages are referred to as "codons." The process of mapping codons to amino acids is known as the "genetic code." Each codon precisely represents one amino acid, with the exception of "stop codons" that signal the end of a message. Although there are 64 codons, only 21 messages need to be conveyed (representing the 20 amino acids and the "stop" signal), resulting in some amino acids and the stop signal being represented by multiple codons. This phenomenon is known as the redundancy of the genetic code.
Translation¶
In the context of genomics, translation is the mechanism by which the information contained in messenger RNA (mRNA) guides the incorporation of amino acids in the course of protein synthesis. This process unfolds on ribosomes located within the cell cytoplasm or endoplasmic reticulum (ER), where mRNA is interpreted and transformed into the sequence of amino acids forming the protein being produced.
Ribosome¶
A ribosome is a cellular structure composed of both RNA and protein, and it serves as the site for protein synthesis within the cell. The ribosome interprets the sequence of messenger RNA (mRNA) and converts this genetic code into a precise sequence of amino acids, which assemble into elongated chains that ultimately fold into proteins. The ribosome functions as a docking point for transfer RNA molecules, which match the base sequence on the messenger RNA. Every three-letter codon on the mRNA corresponds to the anticodon on a specific transfer RNA, facilitating the addition of a particular amino acid to the growing protein chain. Once the protein synthesis process is complete, the ribosome disassembles.
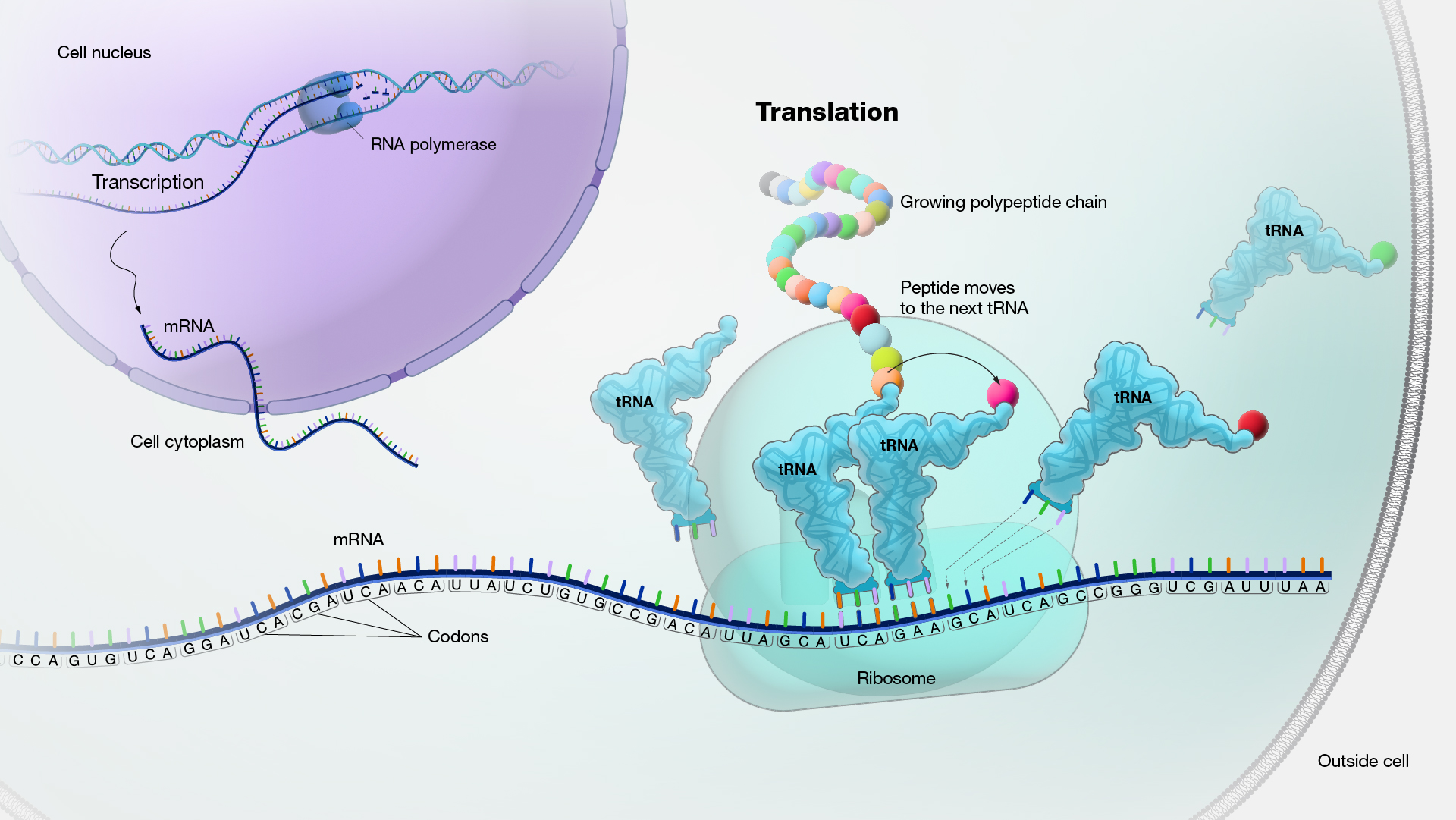
Figure 18. The mechanism of translation (From NIH Genetics Glossary)
Transfer RNA (tRNA)¶
Transfer RNA (tRNA), a compact RNA molecule, assumes a pivotal role in the process of protein synthesis. Acting as an adapter, tRNA bridges the gap between the messenger RNA (mRNA) molecule and the developing sequence of amino acids forming a protein. With each addition of an amino acid to the chain, a specific tRNA pairs up with its corresponding sequence on the mRNA, ensuring that the correct amino acid is incorporated into the protein under construction. In the construction of a protein, DNA functions as the recipe, and the chef represents the ribosomal machinery actively assembling the meal. In this culinary metaphor, tRNA assumes the crucial role of that essential individual in the kitchen who retrieves the precise amino acids needed as the protein is being created in accordance with the DNA code. Thus, tRNA's distinctive responsibility is to guarantee the precise transfer of the right amino acid into the expanding protein chain.
As previously mentioned, the genetic code outlines the correspondence between codons and amino acids. One end of the folded tRNA comprises the "anticodon loop," which presents a sequence complementary to the mRNA's codon. The opposite end of the tRNA is known as the acceptor stem, housing the attachment site for amino acids. With the assistance of aminoacyl tRNA synthetase, the amino acid that corresponds to the anticodon becomes covalently linked to the acceptor stem. During the translation process, a tRNA's anticodon pairs with a codon in a messenger RNA (mRNA) within the ribosome, thus providing the subsequent amino acid necessary for protein synthesis.
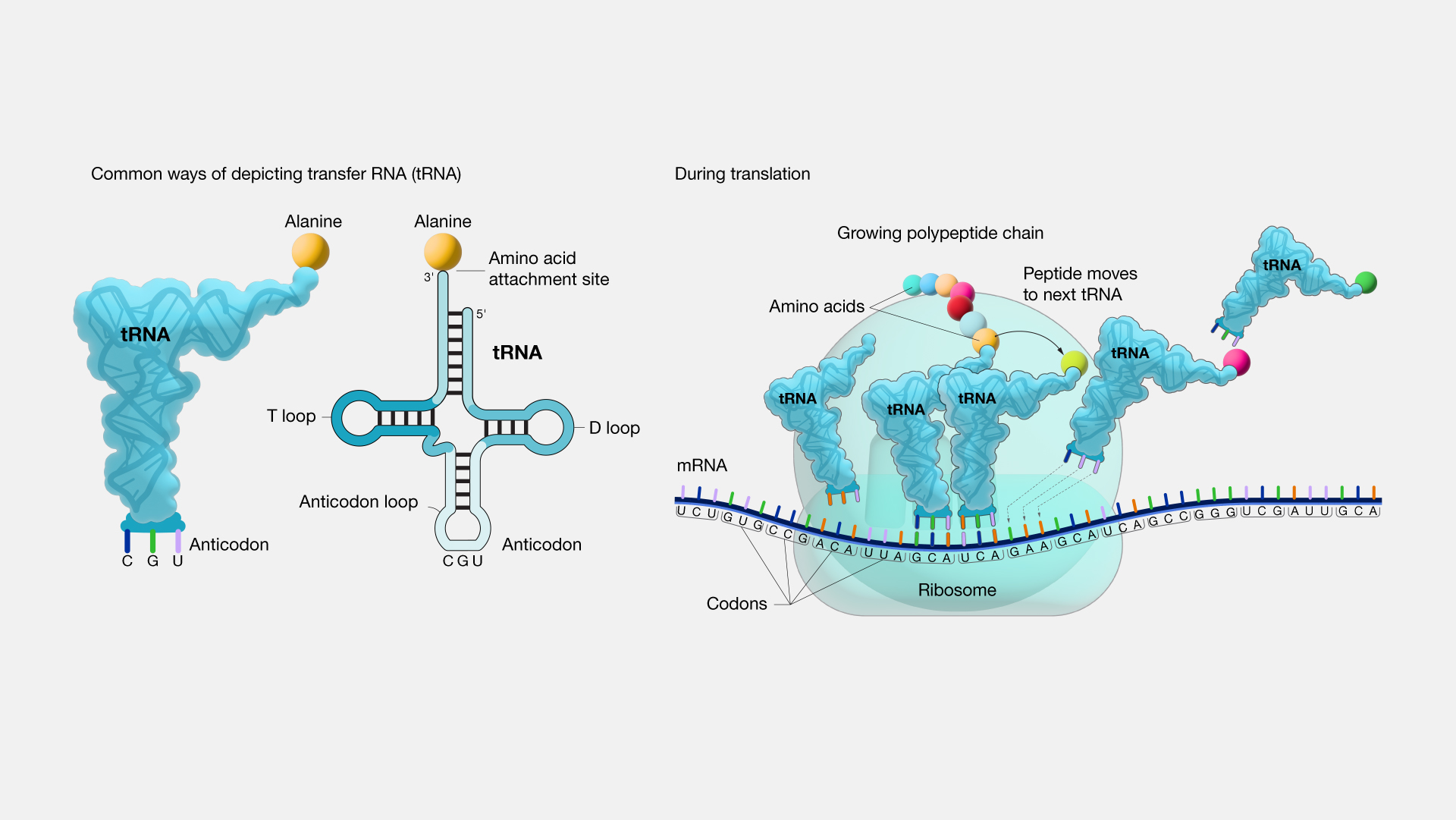
Figure 19. The structure of tRNAs and their role in translation (From NIH Genetics Glossary)
Codon¶
A codon, whether in DNA or RNA, comprises a sequence of three nucleotides, forming a trinucleotide. It serves as a fundamental unit of genomic information, encoding either a specific amino acid or marking the conclusion of protein synthesis through stop signals. The genetic code encompasses 64 distinct codons, with 61 of them designating amino acids and the remaining 3 functioning as stop signals. For example, a messenger RNA codon like GCA signifies the incorporation of the amino acid alanine into the protein chain, while the messenger RNA stop codon UAG signifies the conclusion of that protein's synthesis.
Anticodon¶
An anticodon represents a trinucleotide sequence located at one end of a transfer RNA (tRNA) molecule. This sequence is inherently complementary to a corresponding codon within the messenger RNA (mRNA) sequence. In the course of protein synthesis, each time an amino acid is introduced to an evolving polypeptide, a tRNA's anticodon pairs precisely with its complementary codon on the mRNA, thereby ensuring that the appropriate amino acid becomes a part of the polypeptide. For instance, a messenger RNA codon like GCA corresponds with the transfer RNA possessing the anticodon CGU, and this specific tRNA transports the amino acid known as alanine, ultimately incorporating it into the growing protein chain.
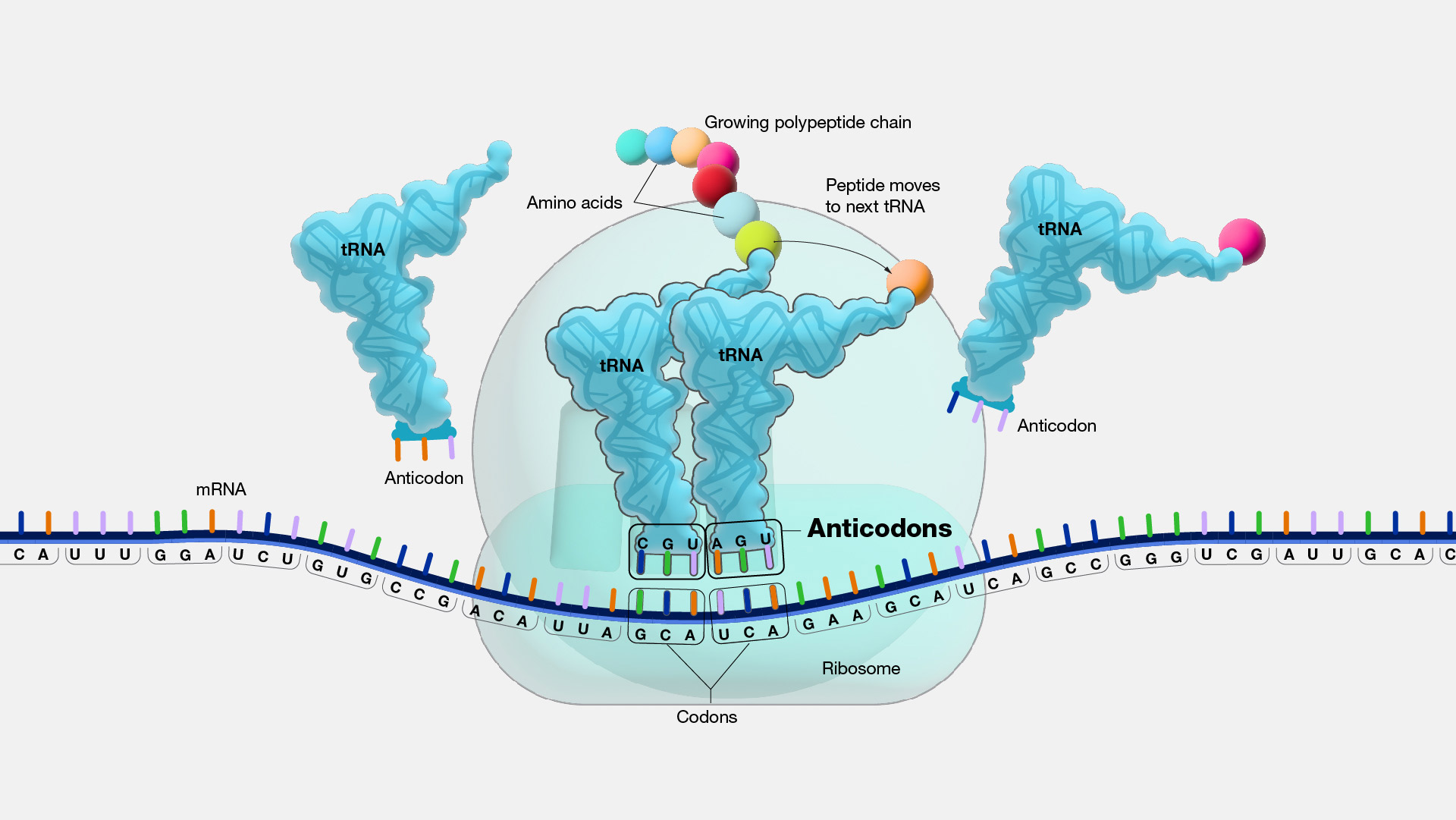
Figure 20. Codons on mRNA and anticodons on tRNA (From NIH Genetics Glossary)
Amino acids¶
An amino acids serve as the units responsible for constructing proteins. There exists a total of 20 distinct amino acids. A protein comprises one or more amino acid chains, referred to as polypeptides, whose sequence is dictated by the instructions found within a gene. While some amino acids can be produced within the body, others, known as essential amino acids, must be sourced from an individual's diet. Remarkably, all the instructions for generating these amino acids and building them into your diverse array of proteins are encapsulated within your genome! Visualize these 20 amino acids as individual pearls, intricately strung together like a long necklace, forming the building blocks of proteins.
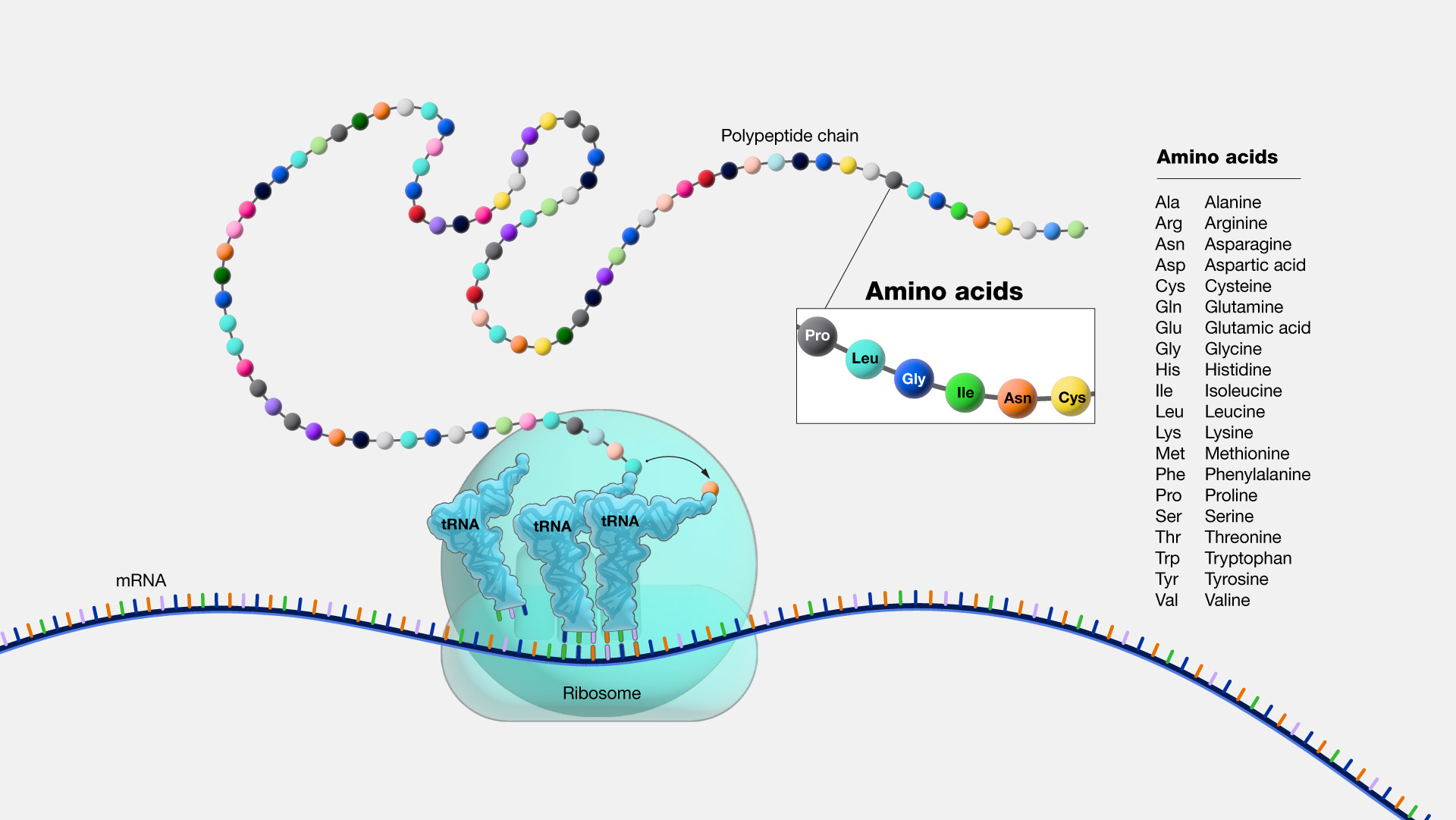
Figure 21. Aminoacids used during translation to build peptide molecule (From NIH Genetics Glossary)
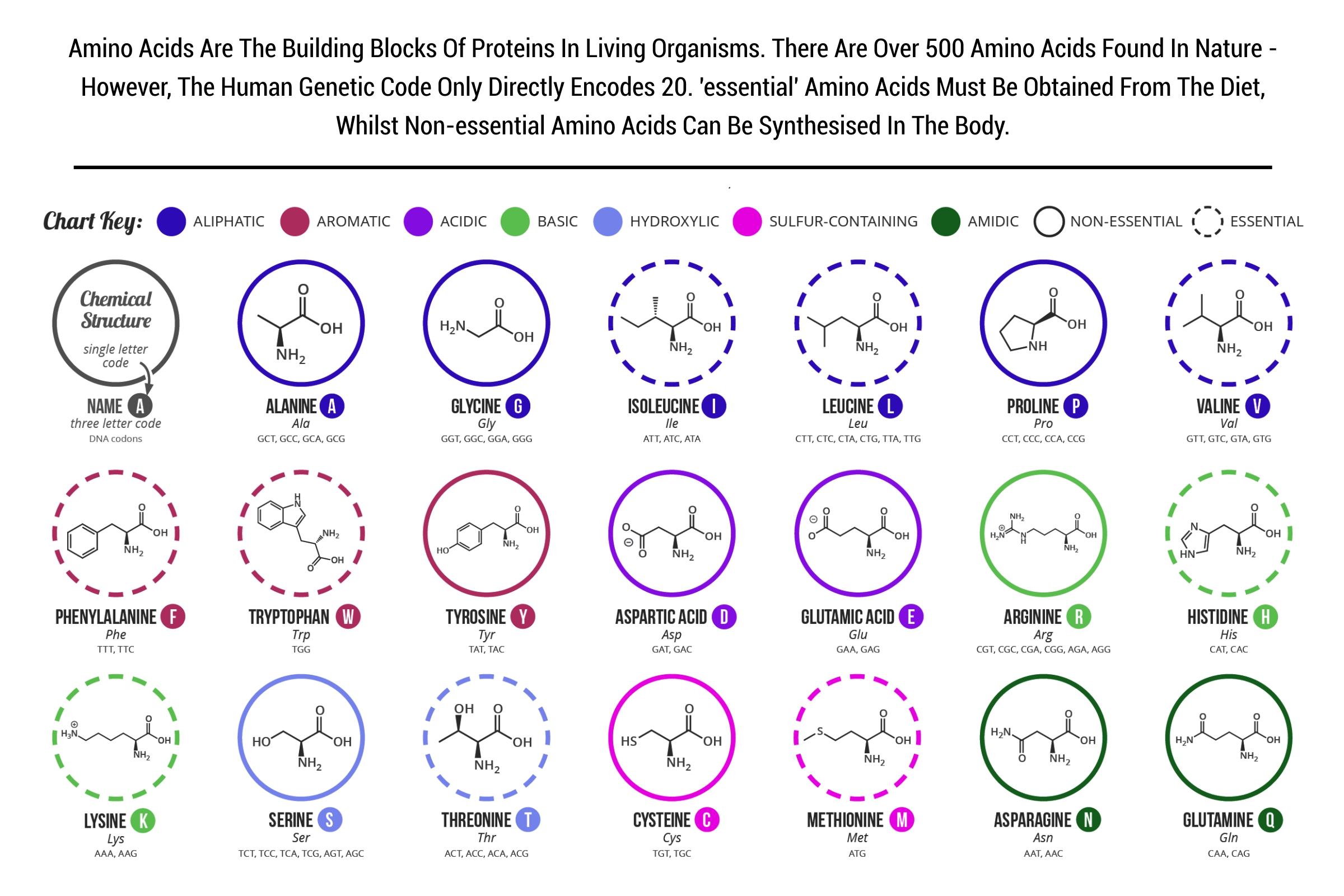
Figure 22. Aminoacids (From)
Peptide¶
A peptide represents a brief sequence of amino acids, usually consisting of 2 to 50 residues, connected by chemical links known as peptide bonds. In the case of a more extensive sequence, containing 51 or more amino acids, it's referred to as a polypeptide. The proteins crafted within cells are constructed from one or more of these polypeptides.
Proteins¶
Proteins are intricate, large molecules with diverse and vital roles in the body. They are indispensable for most cellular functions and play a crucial part in structuring, regulating, and facilitating the functioning of the body's tissues and organs. A protein comprises one or more extended, intricately folded chains of amino acids, each referred to as a polypeptide, with their sequences dictated by the DNA code found in protein-encoding genes.
Some of the more well-known proteins are those that contribute to the formation of structures, such as muscle tissue. Additionally, enzymes are a type of protein that are particularly important because they fold and serve as catalysts in the chemical reactions necessary to maintain life within the body.
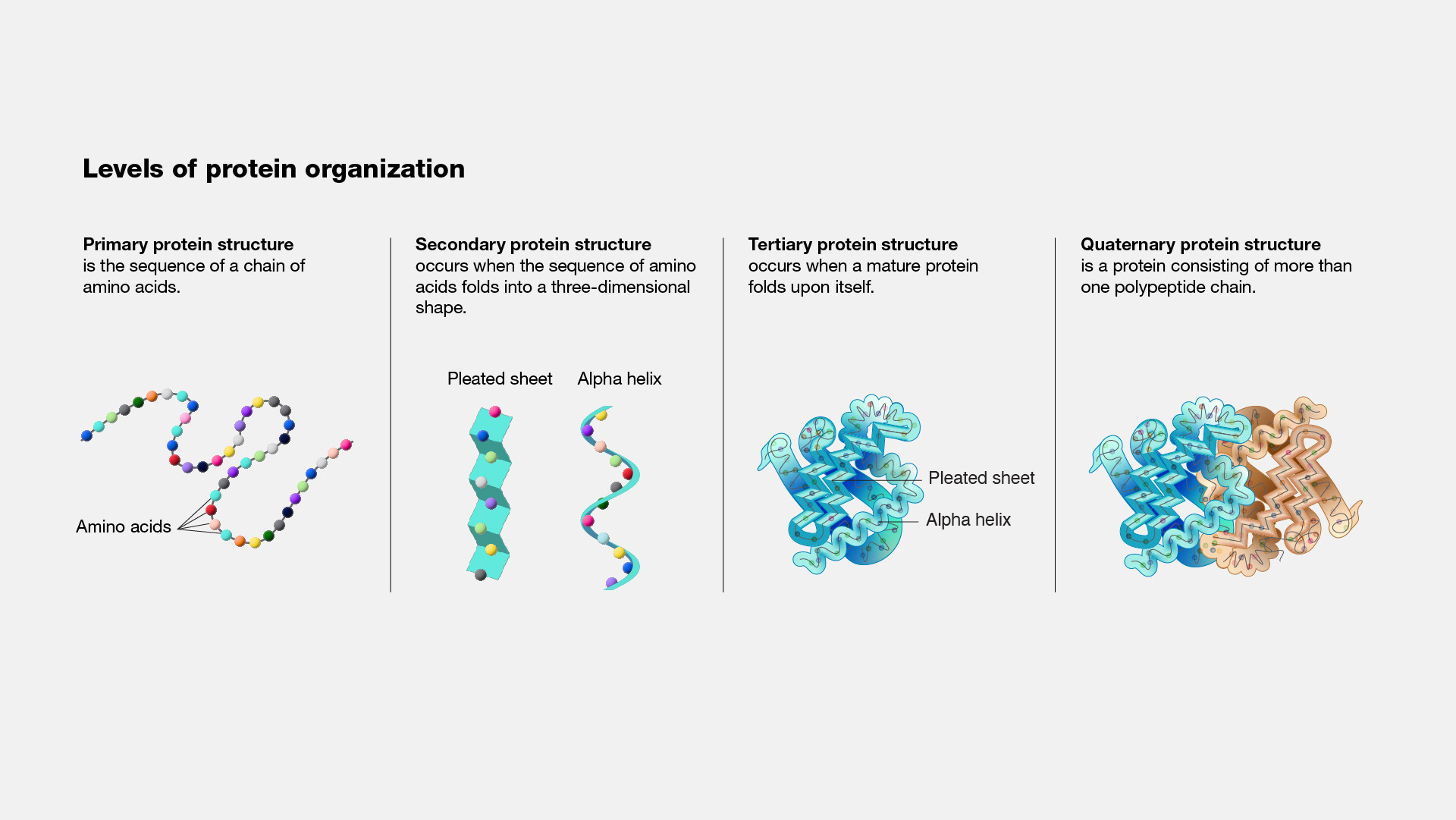
Figure 23. Levels of protein structures during protein folding (From NIH Genetics Glossary)

Figure 24. Levels of protein structures (From Liu et.al)
Decoding protein messages¶
We can utilize the genetic code to interpret blueprints for proteins from DNA or RNA molecules. In addition to the previously mentioned stop codons, we also need to consider start codons when determining which protein sequence is represented by a DNA or RNA sequence. Unlike stop codons, there aren't codons specifically dedicated to indicating the start of a protein-coding region. The AUG codon in RNA (or ATG in DNA) serves as the start of a protein-coding region and encodes the amino acid methionine. The start codon is translated, so the resulting protein will commence with a methionine, which can be removed post-translationally if needed. If an AUG codon appears within a protein-coding sequence, it doesn't have any special meaning and simply encodes methionine in that context. Let's consider a few examples.
Imagine we have the following RNA sequence:
AUGUAUGAGGGUACUAAUUAA
To decode this message manually, we first identify the start codon, which defines the locations of the codons. Then, we visually delineate the breaks between the codons. For clarity, we'll insert spaces between each pair of codons.
AUG UAU GAG GGU ACU AAU UAA
Now, we can look up each of these codons in the genetic code provided above, starting with the start codon, which does get translated. When we look up AUG in the genetic code, we find that it encodes the amino acid Met, which stands for Methionine. The next codon, UAU, encodes the amino acid Tyr, or Tyrosine. If we continue this process until we reach a stop codon, we end up with the protein sequence:
Met - Tyr - Glu - Gly - Thr - Asn
The final codon, UAA, represents a stop codon, which doesn't translate into anything and simply terminates the message.
In this example, our sequence starts with the start codon and ends with a stop codon, but this may not always be the case when examining an RNA sequence. Let's work through another example to illustrate this point:
CUUUUAUGCCUCGUCGUAGUGUGGAAUGAUGGCGUUC
Again, we first identify the location of the start codon and insert spaces in the sequence to help identify the codons.
CUUUU AUG CCU CGU CGU AGU GUG GAA UGA UGG CGU UC
In this case, we see that there are a few bases before the start codon, but we didn't separate them since they are not relevant to this task and precede the start codon. Without referring to the genetic code, we don't yet know where the stop codon is in this sequence (or if there is one). Therefore, we inserted spaces between sequences starting with the start codon and continued until the end of the sequence. Note that we don't have a complete codon at the end of the sequence. Hopefully, we will find a stop codon before reaching that point. If not, we likely have an incomplete and therefore probably useless message. Starting with the start codon, we decode the RNA sequence as follows:
Met - Pro - Arg - Arg - Ser - Val - Glu
Since UGA encodes a stop codon, this message ends before reaching the end of the sequence. The bases following the stop codon are not part of the protein message encoded by this DNA.
Manually translating protein sequences is not particularly efficient, especially for longer sequences, as proteins are usually much longer than six or seven amino acids. For longer sequences, it becomes a slow and error-prone process. In such cases, it is beneficial to identify or develop software to assist with the task. The scikit-bio Python library offers functionality for translating DNA or RNA sequences into protein sequences. This can be achieved using Python 3 as follows:
Python 3 is a widely used programming language in bioinformatics. If you're not familiar with Python 3, don't worry, as we'll explain the code's functionality. If you wish to learn Python 3, you can refer to resources like Introduction to Python. scikit-bio is a collection of tools for bioinformatics designed for use with Python 3.
import skbio
# the following sequence is derived from NCBI reference sequence NM_005368.3
protein = skbio.RNA(
"AUGAAACCCCAGCUGUUGGGGCCAGGACACCCAGUGAGCCCAUACUUGCUCUUUUUGUCUUCUUCAGACUGCGCCAUGGG"
"GCUCAGCGACGGGGAAUGGCAGUUGGUGCUGAACGUCUGGGGGAAGGUGGAGGCUGACAUCCCAGGCCAUGGGCAGG"
"AAGUCCUCAUCAGGCUCUUUAAGGGUCACCCAGAGACUCUGGAGAAGUUUGACAAGUUCAAGCACCUGAAGUCAGAG"
"GACGAGAUGAAGGCGUCUGAGGACUUAAAGAAGCAUGGUGCCACCGUGCUCACCGCCCUGGGUGGCAUCCUUAAGAA"
"GAAGGGGCAUCAUGAGGCAGAGAUUAAGCCCCUGGCACAGUCGCAUGCCACCAAGCACAAGAUCCCCGUGAAGUACC"
"UGGAGUUCAUCUCGGAAUGCAUCAUCCAGGUUCUGCAGAGCAAGCAUCCCGGGGACUUUGGUGCUGAUGCCCAGGGG"
"GCCAUGAACAAGGCCCUGGAGCUGUUCCGGAAGGACAUGGCCUCCAACUACAAGGAGCUGGGCUUCCAGGGCUAGGC"
"CCCUGCCGCUCCCACCCCCACCCAUCUGGGCCCCGGGUUCAAGAGAGAGCGGGGUCUGAUCUCGUGUAGCCAUAUAG"
"AGUUUGCUUCUGAGUGUCUGCUUUGUUUAGUAGAGGUGGGCAGGAGGAGCUGAGGGGCUGGGGCUGGGGUGUUGAAG"
"UUGGCUUUGCAUGCCCAGCGAUGCGCCUCCCUGUGGGAUGUCAUCACCCUGGGAACCGGGAGUGGCCCUUGGCUCAC"
"UGUGUUCUGCAUGGUUUGGAUCUGAAUUAAUUGUCCUUUCUUCUAAAUCCCAACCGAACUUCUUCCAACCUCCAAAC"
"UGGCUGUAACCCCAAAUCCAAGCCAUUAACUACACCUGACAGUAGCAAUUGUCUGAUUAAUCACUGGCCCCUUGAAG"
"ACAGCAGAAUGUCCCUUUGCAAUGAGGAGGAGAUCUGGGCUGGGCGGGCCAGCUGGGGAAGCAUUUGACUAUCUGGA"
"ACUUGUGUGUGCCUCCUCAGGUAUGGCAGUGACUCACCUGGUUUUAAUAAAACAACCUGCAACAUCUCA"
).translate(stop='require')
protein
Protein
---------------------------------------------------------------------
Stats:
length: 179
has gaps: False
has degenerates: False
has definites: True
has stops: False
---------------------------------------------------------------------
0 MKPQLLGPGH PVSPYLLFLS SSDCAMGLSD GEWQLVLNVW GKVEADIPGH GQEVLIRLFK
60 GHPETLEKFD KFKHLKSEDE MKASEDLKKH GATVLTALGG ILKKKGHHEA EIKPLAQSHA
120 TKHKIPVKYL EFISECIIQV LQSKHPGDFG ADAQGAMNKA LELFRKDMAS NYKELGFQG
The preceding step effectively translated an RNA sequence into a protein sequence and displayed the result on the screen. It's worth noting that we previously used three-letter codes to represent amino acids, while scikit-bio employs one-letter codes for amino acid representation. One-letter codes are more commonly used in practice due to their brevity.
Limitations of this analogy¶
Genomes encompass messages beyond protein sequences. In reality, the messages encoded by DNA in our genomes are more intricate than a base 4 numerical system. For instance, the structural conformation adopted by a chromosomal region can influence the expression of genes in that region, leading to significant phenotypic consequences. Similarly, variations in mRNA splicing produce different proteins from the same DNA sequence. Our genomes contain higher-level messages. Therefore, while we can draw some parallels between the information stored in our genomes and the storage of data in computers, our genomes are not merely executable programs. Even the simplest cellular organisms exhibit far greater complexity than humanity's most intricate machines. As Herman Dune noted, "An airplane is nothing if you compare it to a pelican."
This discussion also omits the fact that additional characters are sometimes employed to represent uncertainty in our knowledge of a DNA sequence or to succinctly convey more than one sequence. The IUPAC nucleic acid notation is the notation used in this chapter, where A, C, G, and T represent adenine, cytosine, guanine, and thymine, respectively. This notation defines other characters as well. For instance, N signifies either A, C, G, or T, often encountered in DNA sequence readouts where the base couldn't be conclusively determined. These "degenerate" characters can't be represented within the base 4 numerical system discussed here, and they don't naturally exist but are used for discussing DNA sequences.
Biological Data Sources and Types¶
The field of translational bioinformatics has been significantly influenced by technological advancements in data generation from various biological systems, encompassing DNA sequence data, RNA expression levels, methylation patterns, other epigenetic markers, proteomics, and metabolomics (Figure 25). Over the past decade, there has been a continuous growth in data volume due to these technological innovations, prompting researchers to create complementary analytical tools. Notably, in addition to collecting data from whole-blood or specific tissue samples, there is a swift progression in the capability to gather such data from individual cells.
Various analytical methods have been created to pinpoint the genetic variations responsible for complex traits. For instance, the identification of DNA sequence variations can occur through techniques like linkage analysis within family-related data and association studies in both family and population-based datasets. Additionally, the connection between the phenotypic outcome and variations in other high-throughput omic measurements, such as gene expression (via microarrays and RNA sequencing), epigenetic changes (using methylation arrays, methylation sequencing, or chromatin immunoprecipitation followed by sequencing), and protein variations (measured in metabolomic or proteomic studies), is now a common practice. Traditionally, each type of data has been separately considered to investigate their associations with biological processes. Through these methodologies, we've managed to piece together some of the complex-trait genetic architecture and fundamental biological pathways.
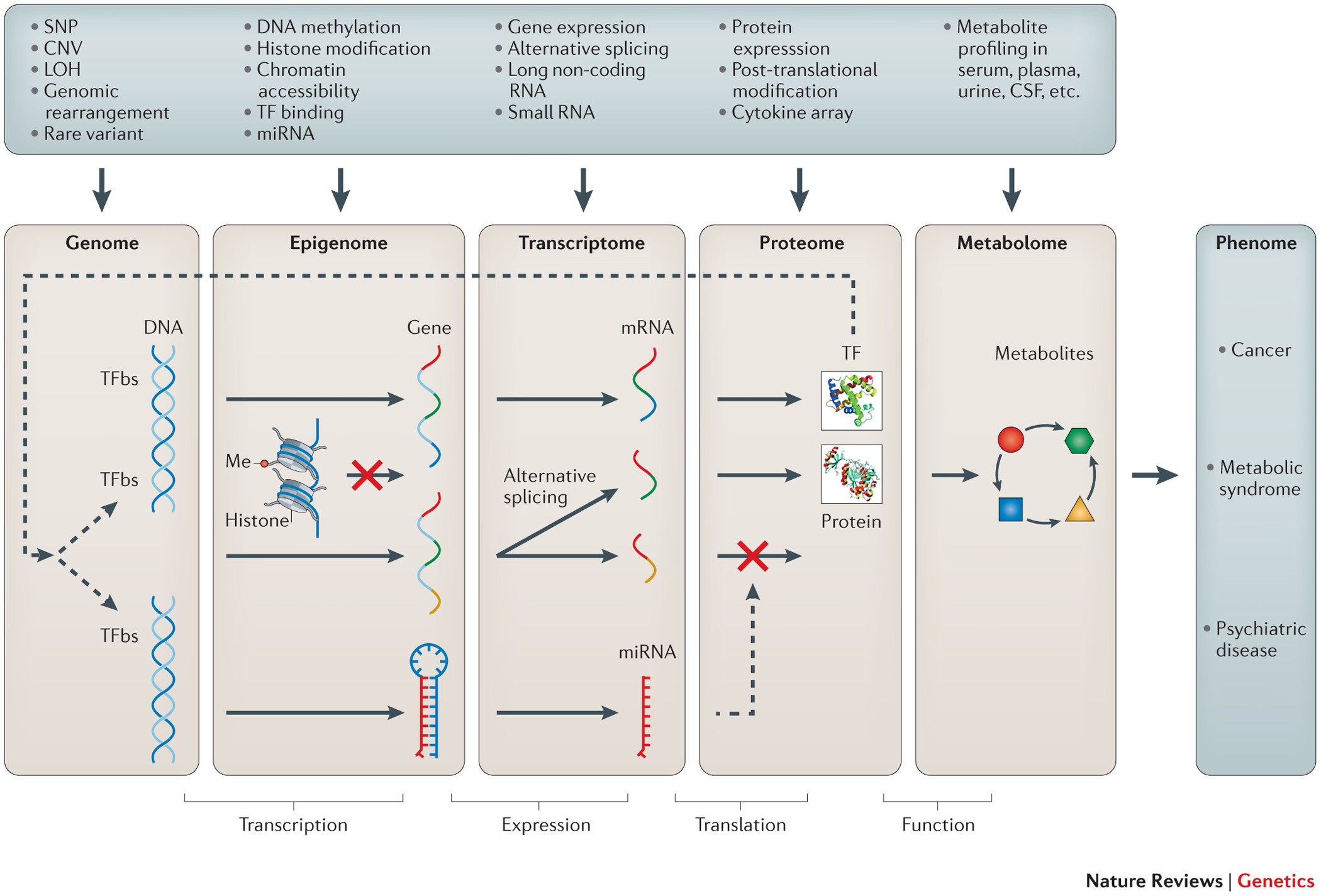
Figure 25. Heterogeneous genomic data exist within and between levels, for example, single-nucleotide polymorphism (SNP), copy number variation (CNV), loss of heterozygosity (LOH) and genomic rearrangement, such as translocation, at the genome level; DNA methylation, histone modification, chromatin accessibility, transcription factor (TF) binding and micro RNA (miRNA) at the epigenome level; gene expression and alternative splicing at the transcriptome level; protein expression and post-translational modification at the proteome level; and metabolite profiling at the metabolome level. Arrows indicate the flow of genetic information from the genome level to the metabolome level and, ultimately, to the phenome level. The red crosses indicate inactivation of transcription or translation. CSF, cerebrospinal fluid; Me, methylation; TFBS, transcription factor-binding site. (From Ritchie et.al)
Traditionally, networks were established by gathering information from scientific literature regarding specific molecules. The ability to measure a single omic layer has become common. The concept of trans-omics is emerging as we connect data from multiple omic measurements. An omic layer refers to a group of molecules with similar chemical characteristics, such as the genome, transcriptome, proteome, and metabolome. These layers can be measured using advanced technologies like next-generation sequencers (NGS), microarrays, mass spectrometry, electron microscopy and nuclear magnetic resonance (NMR).

Figure 26. Trans-Omic Network Across Multiple Omic Layers. (From Yugi et.al)
Summary¶
In this section we explored basics of biological systems and different data types extracted from biological molecules. We additionally introduced the genetic code, and used the genetic code to decode protein sequences from RNA sequences.
Videos¶
The Central Dogma of Biology¶
pip install ipython
from IPython.display import HTML
HTML('<iframe width="1100" height="630" src="https://www.youtube.com/embed/9kOGOY7vthk?si=5K4iu97bhmCTw1nN" frameborder="0" allowfullscreen></iframe>')
/usr/local/lib/python3.11/site-packages/IPython/core/display.py:431: UserWarning: Consider using IPython.display.IFrame instead
warnings.warn("Consider using IPython.display.IFrame instead")
The Inner Life of the Cell¶
from IPython.display import HTML
HTML('<iframe width="1100" height="630" src="https://www.youtube.com/embed/MZ47-G4XKDw?si=z9DO2cIRta_rFVxF" frameborder="0" allowfullscreen></iframe>')
/usr/local/lib/python3.11/site-packages/IPython/core/display.py:431: UserWarning: Consider using IPython.display.IFrame instead
warnings.warn("Consider using IPython.display.IFrame instead")